- Учителю
- Курс лекций по дисциплине Основы теории информации
Курс лекций по дисциплине Основы теории информации
В.В. Бобрышева
ОСНОВЫ
ТЕОРИИ ИНФОРМАЦИИ
Учебное пособие
Курск - 2016
Настоящее учебное пособие разработано в соответствии с Федеральным государственным образовательным стандартом среднего специального образования по специальности 09.02.05 Прикладная информатика (по отраслям) по дисциплине ОП.06. Основы теории информации.
Оглавление
Теория информации рассматривается как существенная часть кибернетики.
Кибернетика - это наука об общих законах получения, хранения, передачи и переработки информации. Ее основной предмет исследования - это так называемые кибернетические системы, рассматриваемые абстрактно, вне зависимости от их материальной природы. Примеры кибернетических систем: автоматические регуляторы в технике, ЭВМ, мозг человека или животных, биологическая популяция, социум. Часто кибернетику связывают с методами искусственного интеллекта, т.к. она разрабатывает общие принципы создания систем управления и систем для автоматизации умственного труда. Основными разделами (они фактически абсолютно самостоятельны и независимы) современной кибернетики считаются: теория информации, теория алгоритмов, теория автоматов, исследование операций, теория оптимального управления и теория распознавания образов.
Родоначальниками кибернетики (датой ее рождения считается 1948 год, год соответствующей публикации) считаются американские ученые Норберт Винер (Wiener, он - прежде всего) и Клод Шеннон (Shannon, он же основоположник теории информации).
Винер ввел основную категорию кибернетики - управление, показал существенные отличия этой категории от других, например, энергии, описал несколько задач, типичных для кибернетики, и привлек всеобщее внимание к особой роли вычислительных машин, считая их индикатором наступления новой НТР. Выделение категории управления позволило Винеру воспользоваться понятием информации, положив в основу кибернетики изучение законов передачи и преобразования информации.
Сущность принципа управления заключается в том, что движение и действие больших масс или передача и преобразование больших количеств энергии направляется и контролируется при помощи небольших количеств энергии, несущих информацию. Этот принцип управления лежит в основе организации и действия любых управляемых систем: автоматических устройств, живых организмов и т. п. Подобно тому, как введение понятия энергии позволило рассматривать все явления природы с единой точки зрения и отбросило целый ряд ложных теорий, так и введение понятия информации позволяет подойти с единой точки зрения к изучению самых различных процессов взаимодействия в природе.
В СССР значительный вклад в развитие кибернетики внесли академики Берг А. И. и Глушков В. М.
В нашей стране в 50-е годы кибернетика была объявлена лженаукой и была практически запрещена, что не мешало, однако, развиваться всем ее важным разделам (в том числе и теории информации) вне связи с обобщающим словом «кибернетика».
Теория информации тесно связана с такими разделами математики как теория вероятностей и математическая статистика, а также прикладная алгебра, которые предоставляют для нее математический фундамент. С другой стороны теория информации исторически и практически представляет собой математический фундамент теории связи. Часто теорию информации вообще рассматривают как одну из ветвей теории вероятностей или как часть теории связи. Таким образом, предмет «Теория информации» весьма узок, т.к. зажат между «чистой» математикой и прикладными (техническими) аспектами теории связи.
Теория информации представляет собой математическую теорию, посвященную измерению информации, ее потока, «размеров» канала связи и т.п., особенно применительно к радио, телеграфии, телевидению и к другим средствам связи. Первоначально теория была посвящена каналу связи, определяемому длиной волны и частотой, реализация которого была связана с колебаниями воздуха или электромагнитным излучением. Обычно соответствующий процесс был непрерывным, но мог быть и дискретным, когда информация кодировалась, а затем декодировалась. Кроме того, теория информации изучает методы построения кодов, обладающих полезными свойствами.
Информационная культура.
Количество информации в современном обществе стремительно нарастает, человек оказывается погруженным в море информации. Для того чтобы в этом море «не утонуть», необходимо обладать информационной культурой, то есть знаниями и умениями в области информационных и коммуникационных технологий, а также быть знакомым с юридическими и этическими нормами в этой сфере.
Компьютеры и информационные технологии интенсивно проникают и в сферу материального производства. Наступило время, когда профессионал (юрист, инженер, экономист, социолог, журналист) - уже с трудом справляется с потоками информации. Специалисту, чтобы на должном уровне выполнять свои обязанности, необходимы инструментарий и методология его применения для обработки информации.
Это можно сравнить с использованием средств передвижения: теоретически человек может пешком преодолеть любое расстояние, но современный темп жизни просто немыслим без применения автомобиля, поезда, самолета. Тоже самое происходит и с информацией (ее обработкой) теоретически человек может сам переработать без компьютера любую информацию, но сделает эффективнее, если овладеет знаниями и умениями, которыми располагают информационные технологии.
Кто видел, как работают солидные фирмы, видел, что информационные технологии - необходимый атрибут профессиональной пригодности в обществе. Претендент на престижную работу должен обладать не только профессиональными знаниями и владеть иностранным языком, но и свободно владеть навыками работы на ПК.
С развитием коммуникационных технологий и мобильной связи все большее количество людей осуществляют свою производственную деятельность дистанционно, то есть работая дома, а не в офисе (в США более 10 миллионов человек). Все большее распространение получает дистанционное образование и поиск работы через Интернет.
Информационное общество - это общество, в котором большая часть населения занята получением, переработкой, передачей и хранением информации.
Понятие информации.
Термин «информация» происходит от латинского слова «informatio» , что означает сведения, разъяснения, изложение.
Несмотря на широкое распространение этого термина, понятие информации является одним из самых дискуссионных в науке. В настоящее время наука пытается найти общие свойства и закономерности, присущие многогранному понятию информация, но пока это понятие во многом остается интуитивным и получает различные смысловые наполнения в различных отраслях человеческой деятельности:
• в обиходе информацией называют любые данные или сведения, которые кого-либо интересуют. Например, сообщение о каких-либо событиях, о чьей-либо деятельности и т.п. «Информировать» в этом смысле означает «сообщить нечто, неизвестное раньше»;
• в технике под информацией понимают сообщения, передаваемые в форме знаков или сигналов;
• в кибернетике под информацией понимает ту часть знаний, которая используется для ориентирования, активного действия, управления, т.е. в целях сохранения, совершенствования, развития системы (Н. Винер).
Клод Шеннон, американский учёный, заложивший основы теории информации - науки, изучающей процессы, связанные с передачей, приёмом, преобразованием и хранением информации, - рассматривает информацию как снятую неопределенность наших знаний о чем-то.
Приведем еще несколько определений:
-
Информация - это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний (Н.В. Макарова);
-
Информация - это отрицание энтропии (Леон Бриллюэн);
-
Информация - это мера сложности структур (Моль);
-
Информация - это отраженное разнообразие (Урсул);
-
Информация - это содержание процесса отражения (Тузов);
-
Информация - это вероятность выбора (Яглом).
Современное научное представление об информации очень точно сформулировал Норберт Винер, «отец» кибернетики. А именно:
Информация - это обозначение содержания, полученного из внешнего мира в процессе нашего приспособления к нему и приспособления к нему наших чувств.
Люди обмениваются информацией в форме сообщений. Сообщение - это форма представления информации в виде речи, текстов, жестов, взглядов, изображений, цифровых данных, графиков, таблиц и т.п.
Одно и то же информационное сообщение (статья в газете, объявление, письмо, телеграмма, справка, рассказ, чертёж, радиопередача и т.п.) может содержать разное количество информации для разных людей - в зависимости от их предшествующих знаний, от уровня понимания этого сообщения и интереса к нему.
Так, сообщение, составленное на японском языке, не несёт никакой новой информации человеку, не знающему этого языка, но может быть высокоинформативным для человека, владеющего японским. Никакой новой информации не содержит и сообщение, изложенное на знакомом языке, если его содержание непонятно или уже известно.
Информация есть характеристика не сообщения, а соотношения между сообщением и его потребителем. Без наличия потребителя, хотя бы потенциального, говорить об информации бессмысленно.
В случаях, когда говорят об автоматизированной работе с информацией посредством каких-либо технических устройств, обычно в первую очередь интересуются не содержанием сообщения, а тем, сколько символов это сообщение содержит.
Применительно к компьютерной обработке данных под информацией понимают некоторую последовательность символических обозначений (букв, цифр, закодированных графических образов и звуков и т.п.), несущую смысловую нагрузку и представленную в понятном компьютеру виде. Каждый новый символ в такой последовательности символов увеличивает информационный объём сообщения.
Не смотря на то, что человеку постоянно приходится иметь дело с информацией (он получает ее с помощью органов чувств) строго научного определения, что же такое информация, не существует. В тех случаях когда наука не может дать четкого определения какому - то предмету или явлению, люди пользуются понятиями.
Понятия отличаются от определений тем, что разные люди при разных обстоятельствах могут вкладывать в них разный смысл
Слово «информация» происходит от латинского слова informatio, что в переводе означает изложение, разъяснение, ознакомление. Понятие «информация» является базовым в курсе информатики, невозможно дать его определение через другие, более «простые» понятия.
В геометрии, например, невозможно выразить содержание базовых понятий «точка», «луч», «плоскость» через более простые понятия. Содержание основных, базовых понятий в любой науке должно быть пояснено на примерах или выявлено путем их сопоставления с содержанием других понятий. Поэтому в информатике понятию «информация» определение не дается, оно лишь разъясняется и иллюстрируется конкретными примерами применения данного термина.
В бытовом смысле под информацией обычно понимают те сведения, которые человек получает от окружающей природы и общества с помощью органов чувств. (5 видов), например:
-
Вкус - горькое, сладкое, кислое, соленое
-
Обоняние - испорченная еда
-
Осязание - горячее, холодное, колючее, мягкое
-
Зрение - лягушка, мягкая игрушка
-
Слух - подъехала машина или летит самолет и т.д.
Так же. наблюдая за природой, общаясь с другими людьми, читая книги и газеты, просматривая телевизионные передачи мы получаем информацию.
Математик рассмотрит это понятие шире и включит в него те сведения, которые человек не получал, а создал сам с помощью умозаключений.
Биолог же пойдет дальше и отнесет к информации те данные, которые человек не получал с помощью органов чувств и не создавал в своем уме, а хранит в себе с момента рождения до смерти. Это генетический код, благодаря которому дети так похожи на своих родителей.
Итак, в различных научных дисциплинах и областях техники существуют разные понятия об информации. Нам же, приступая к изучению информатики надо найти что-то общее, что объединяет различные подходы. И так общая черта есть.
Все отрасли науки и техники, имеющие дело с информацией, сходятся в том, что информацию можно: создавать, передавать (и соответственно принимать), хранить и обрабатывать
Каждая дисциплина решает эти вопросы по-разному. И мы с вами рассмотрим те средства, которые для этого предоставляет информатика.
Информация может существовать в виде:
• текстов, рисунков, чертежей, фотографий
• световых или звуковых сигналов;
• радиоволн;
• электрических и нервных импульсов;
• магнитных записей;
• жестов и мимики;
• запахов и вкусовых ощущений;
• хромосом, посредством которых передаются по наследству признаки и свойства организмов и т.д.
Предметы, процессы, явления материального или нематериального свойства, рассматриваемые с точки зрения их информационных свойств, называются информационными объектами.
Передача информации
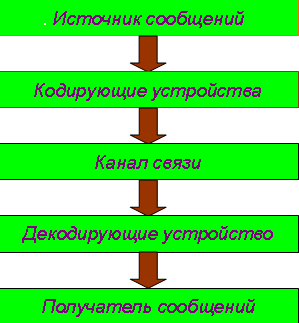
Рис. 1.Общая схема передачи информации
Информация передаётся в форме сообщений от некоторого источника информации к её приёмнику посредством канала связи между ними. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал. Этот сигнал посылается по каналу связи. В результате в приёмнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
Примеры:
1. Сообщение, содержащее информацию о прогнозе погоды, передаётся приёмнику телезрителю) от источника - специалиста-метеоролога посредст-вом канала связи телевизионной передающей аппаратуры и телевизора.
2. Живое существо своими органами чувств (глаз, ухо, кожа, язык и т.д.) воспринимает информацию из внешнего мира, перерабатывает её в определенную последовательность нервных импульсов, передает импульсы по нервным волокнам, хранит в памяти в виде состояния нейронных структур мозга, воспроизводит в виде звуковых сигналов, движений и т.п., использует в процессе своей жизнедеятельности.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Для передачи информации или ее хранения в виде того или иного сообщения требуется определенный способ кодирования. Кодирование своей главной целью имеет сохранение информации и придание ей формы, обеспечивающей полноценную (т. е. без потерь и искажений) передачу информации от источника к получателю.
Об информации, представленной последовательностью знаков, говорят, что она символьная; информацию, представленную посредством какого-либо изображения, называют «видеоинформацией».
Вся информация, циркулирующая в компьютере, закодирована в двух символьном алфавите.
Социально значимые свойства информации. Человек - существо социальное, для общения с другими людьми он должен обмениваться с ними информацией, причем обмен информацией всегда производится на определенном языке - русском, английском и так далее. Участники дискуссии должны владеть тем языком, на котором ведется общение, тогда информация будет понятной всем участникам обмена информацией.
Информация должна быть полезной, тогда дискуссия приобретает практическую ценность. Бесполезная информация создает информационный шум, который затрудняет восприятие полезной информации. Примерами передачи и получения бесполезной информации могут служить некоторые конференции и чаты в Интернете.
Широко известен термин «средства массовой информации» (газеты, радио, телевидение), которые доводят информацию до каждого члена общества. Такая информация должна быть достоверной и актуальной. Недостоверная информация вводит членов общества в заблуждение и может быть причиной возникновения социальных потрясений. Неактуальная информация бесполезна и поэтому никто, кроме историков, не читает прошлогодних газет.
Для того чтобы человек мог правильно ориентироваться в окружающем мире, информация должна быть полной и точной. Задача получения полной и точной информации стоит перед наукой. Овладение научными знаниями в процессе обучения позволяют человеку получить полную и точную информацию о природе, обществе и технике.
Свойства информации.
Свойства информации: достоверность, полнота, избыточность, актуальность, доступность, объективность, полезность.
Свойства информации:
-
достоверность;
-
полнота;
-
ценность;
-
своевременность;
-
понятность;
-
доступность;
-
краткость…
Информация достоверна, если она отражает истинное положение дел. Недостоверная информация может привести к неправильному пониманию или принятию неправильных решений.
Достоверная информация со временем может стать недостоверной, так как она обладает свойством устаревать, то есть перестаёт отражать истинное положение дел.
Информация полна, если её достаточно для понимания и принятия решений. Как неполная, так и избыточная информация сдерживает принятие решений или может повлечь ошибки.
Точность информации определяется степенью ее близости к реальному состоянию объекта, процесса, явления и т.п.
Ценность информации зависит от того, насколько она важна для решения задачи, а также от того, насколько в дальнейшем она найдёт применение в каких-либо видах деятельности человека.
Только своевременно полученная информация может принести ожидаемую пользу. Одинаково нежелательны как преждевременная подача информации (когда она ещё не может быть усвоена), так и её задержка.
Если ценная и своевременная информация выражена непонятным образом, она может стать бесполезной.
Информация становится понятной, если она выражена языком, на котором говорят те, кому предназначена эта информация.
Информация должна преподноситься в доступной (по уровню восприятия) форме. Поэтому одни и те же вопросы по-разному излагаются в школьных учебниках и научных изданиях.
Информацию по одному и тому же вопросу можно изложить кратко (сжато, без несущественных деталей) или пространно (подробно, многословно). Краткость информации необходима в справочниках, энциклопедиях, учебниках, всевозможных инструкциях.
Информацию можно:
-
создавать;
-
передавать;
-
воспринимать;
-
использовать;
-
запоминать;
-
принимать;
-
копировать;
-
формализовать;
-
распространять;
-
преобразовывать;
-
комбинировать;
-
обрабатывать;
-
делит на части;
-
упрощать;
-
собирать;
-
хранить;
-
искать;
-
измерять;
-
разрушать;
-
и др.
Все эти процессы, связанные с определенными операциями над информацией, называются информационными процессами.
Обработка информации - получение одних информационных объектов из других информационных объектов путем выполнения некоторых алгоритмов.
Обработка является одной из основных операций, выполняемых над информацией, и главным средством увеличения объёма и разнообразия информации.
Средства обработки информации - это всевозможные устройства и системы, созданные человечеством, и в первую очередь, компьютер - универсальная машина для обработки информации.
Компьютеры обрабатывают информацию путем выполнения некоторых алгоритмов.
Живые организмы и растения обрабатывают информацию с помощью своих органов и систем.
Информационные ресурсы - это идеи человечества и указания по их реализации, накопленные в форме, позволяющей их воспроизводство.
Это книги, статьи, патенты, диссертации, научно-исследовательская и опытно-конструкторская документация, технические переводы, данные о передовом производственном опыте и др.
Информационные ресурсы (в отличие от всех других видов ресурсов - трудовых, энергетических, минеральных и т.д.) тем быстрее растут, чем больше их расходуют.
Информационная технология - это совокупность методов и устройств, используемых людьми для обработки информации.
Человечество занималось обработкой информации тысячи лет. Первые информационные технологии основывались на использовании счётов и письменности. Около пятидесяти лет назад началось исключительно быстрое развитие этих технологий, что в первую очередь связано с появлением компьютеров.
В настоящее время термин "информационная технология" употребляется в связи с использованием компьютеров для обработки информации. Информационные технологии охватывают всю вычислительную технику и технику связи и, отчасти, бытовую электронику, телевидение и радиовещание.
Народы развитых стран осознают, что совершенствование информационных технологий представляет самую важную, хотя дорогостоящую и трудную задачу.
В настоящее время создание крупномасштабных информационно-технологических систем является экономически возможным, и это обусловливает появление национальных исследовательских и образовательных программ, призванных стимулировать их разработку.
Информатизация общества - организованный социально-экономический и научно-технический процесс создания оптимальных условий для удовлетворения информационных потребностей и реализации прав граждан, органов государственной власти, органов местного самоуправления организаций, общественных объединений на основе формирования и использования информационных ресурсов.
Цель информатизации - улучшение качества жизни людей за счет увеличения производительности и облегчения условий их труда.
Информатизация - это сложный социальный процесс, связанный со значительными изменениями в образе жизни населения. Он требует серьёзных усилий на многих направлениях, включая ликвидацию компьютерной неграмотности, формирование культуры использования новых информационных технологий и др.
Формы адекватности информации.
В процессе обработки информация может менять структуру и форму. Признаком структуры являются элементы информации и их взаимосвязь. Формы представления информации могут быть различны. Основными из них являются: символьная (основана на использовании различных символов), текстовая (текст - это символы, расположенные в определенном порядке), графическая (различные виды изображений), звуковая.
Одной из важнейших характеристик информации является ее адекватность.
Каждой форме адекватности соответствует своя мера количества информации.
В повседневной практике такие понятия, как информация и данные, часто рассматриваются как синонимы. На самом деле между ними имеются различия. Данными называется информация, представленная в удобном для обработки виде. Данные могут быть представлены в виде текста, графики, аудиовизуального ряда. Представление данных называется языком информатики, представляющим собой совокупность символов, соглашений и правил, используемых для общения, отображения, передачи информации в электронном виде.
Адекватность информации - это уровень соответствия образа, создаваемого с помощью информации, реальному объекту, процессу, явлению. От степени адекватности информации зависит правильность принятия решения. Адекватность информации может выражаться в трех формах: синтаксической, семантической и прагматической.
Синтаксическая адекватность отображает формально-структурные характеристики информации, не затрагивая ее смыслового содержания. На синтаксическом уровне учитываются тип носителя и способ представления информации, скорость ее передачи и обработки, размеры кодов представления информации, надежность и Точность преобразования этих кодов и т. д. Информацию, рассматриваемую с таких позиций, обычно называют данными.
Семантическая адекватность определяет степень соответствия образа объекта самому объекту. Здесь учитывается смысловое содержание информации. На этом уровне анализируются сведения, отражаемые информацией, рассматриваются смысловые связи. Таким образом, семантическая адекватность проявляется при наличии единства информации и пользователя. Эта форма служит для формирования понятий и представлений, выявления смысла, содержания информации и ее обобщения.
Прагматическая адекватность отражает соответствие информации цели управления, реализуемой на ее основе. Прагматические свойства информации проявляются при наличии единства информации, пользователя и цели управления. На этом уровне анализируются потребительские свойства информации, связанные с практическим использованием информации, с соответствием ее целевой функции деятельности системы.
Синтаксическая мера информации оперирует с обезличенной информацией, не выражающей смыслового отношения к объекту. На этом уровне объем данных в сообщении измеряется количеством символов в этом сообщении. В современных ЭВМ минимальной единицей измерения данных является бит - один двоичный разряд. Широко используются также более крупные единицы измерения: байт, равный 8 битам; килобайт, равный 1024 байтам; мегабайт, равный 1024 килобайтам, и т. д.
Семантическая мера информации используется для измерения смыслового содержания информации. Наибольшее распространение здесь получила тезаурусная мера, связывающая семантические свойства информации со способностью пользователя принимать поступившее сообщение. Тезаурус - это совокупность сведений, которыми располагает пользователь или система. Максимальное количество семантической информации потребитель получает при согласовании ее смыслового содержания со своим тезаурусом, когда поступающая информация понятна пользователю и несет ему ранее не известные сведения. С семантической мерой количества информации связан коэффициент содержательности, определяемый как отношение количества семантической информации к общему объему данных.
Прагматическая мера информации определяет ее полезность, ценность для процесса управления. Обычно ценность информации измеряется в тех же единицах, что и целевая функция управления системой.
Классификация мер. Для измерения информации вводятся два параметра: количество информации I и объем данных Vд.
Эти параметры имеют разные выражения и интерпретацию в зависимости от рассматриваемой формы адекватности. Каждой форме адекватности соответствует своя мера количества информации и объема данных
Синтаксическая мера информации оперирует с обезличенной информацией, не выражающей смыслового отношения к объекту.
Объем данных Vд в сообщении измеряется количеством символов (разрядов) в этом сообщении. В различных системах счисления один разряд имеет различный вес и соответственно меняется единица измерения данных:
• в двоичной системе счисления единица измерения - бит (bit - binary digit - двоичный разряд). В современных ЭВМ наряду с минимальной единицей измерения данных «бит» широко используется укрупненные единицы измерения байт - 23 бит, слово - 24 бит, двойное слово 25 бит, килобайт - 210 байт; мегабайт - 210 килобайт, гигабайт - 210 мегабайт;
• в десятичной системе счисления единица измерения - дит (десятичный разряд).
Пример 1. Сообщение в двоичной системе в виде восьмиразрядного двоичного кода 10111011 имеет объем данных Vд = 8 бит.
Сообщение в десятичной системе в виде шестиразрядного числа 275903 имеет объем данных Vд= 6 дит.
Количество информации I на синтаксическом уровне определяется в связи с понятием неопределенности состояния системы (энтропии системы). Считается что получение информации о какой-либо системе всегда связано с изменением степени неосведомленности получателя о состоянии этой системы.
Пусть до получения информации потребитель имеет некоторые предварительные (априорные) сведения о системе α. Мерой его неосведомленности о системе является функция H(α), которая в то же время служит и мерой неопределенности состояния системы.
После получения некоторого сообщения β получатель приобрел некоторую дополнительную информацию Iβ(α), уменьшившую его априорную неосведомленность так, что неопределенность состояния системы после получения сообщения β стала Hβ(α).
Тогда количество информации Iβ(α) ξ системе, полученной в сообщении β, определится как
Iβ(α)=H(α)-Hβ(α).
т.е. количество информации измеряется изменением (уменьшением) неопределенности состояния системы. Если конечная неопределенность Hβ(α) ξбратится в нуль, то первоначальное неполное знание заменится полным знанием и количество информации Iβ(α)=H(α). Иными словами, энтропия системы Н(а) может рассматриваться как мера недостающей информации.
Энтропия системы H(α), θмеющая N возможных состояний, согласно формуле Шеннона, равна:
, где Pi - вероятность того, что система находится в i-м состоянии. Для случая, когда все состояния системы равновероятны, т.е. их вероятности равны , ее энтропия определяется соотношением .
Наиболее часто используются двоичные и десятичные логарифмы. Единицами измерения в этих случаях будут соответственно бит и дит.
Коэффициент (степень) информативности (лаконичность) сообщения определяется отношением количества информации к объему данных, т.е., причем 0
С увеличением Y уменьшаются работы по преобразованию информации (данных) в системе. Поэтому стремятся к повышению информативности, для чего разрабатываются специальные методы оптимального кодирования информации.
Семантическая мера информации. Для измерения смыслового содержания информации, т.е. ее количества на семантическом уровне, наибольшее признание получила тезаурусная мера, которая связывает семантические свойства информации со способностью пользователя принимать поступившее сообщение. Для этого используется понятие тезаурус пользователя.
Тезаурус - это совокупность сведений, которыми располагает пользователь или система.
В зависимости от соотношений между смысловым содержанием информации S и тезаурусом пользователя Sp изменяется количество семантической информации Ic воспринимаемой пользователем и включаемой им в дальнейшем в свой тезаурус.
Максимальное количество семантической информации Ic потребитель приобретает при согласовании ее смыслового содержания S со своим тезаурусом Sp, когда поступающая информация понятна пользователю и несет ему ранее не известные (отсутствующие в его тезаурусе) сведения. Следовательно, количество семантической информации в сообщении, количество новых знаний, получаемых пользователем, является величиной относительной. Одно и то же сообщение может иметь смысловое содержание для компетентного пользователя и быть бессмысленным (семантический шум) для пользователя некомпетентного.
Относительной мерой количества семантической информации может служить коэффициент содержательности C, который определяется как отношение количества семантической информации к ее объему:
Прагматическая мера информации. Эта мера определяет полезность информации (ценность) для достижения пользователем поставленной цели. Эта мера также величина относительная, обусловленная особенностями использования этой информации в той или иной системе. Ценность информации целесообразно измерять в тех же самых единицах (или близких к ним), в которых измеряется целевая функция.
Для сопоставления введенные меры информации представим в таб. 1
Единицы измерения
Примеры
(для компьютерной области)
Синтаксическая:
Шенноновский подход
компьютерный подход
Степень уменьшения неопределенности
Единицы представления информации
Вероятность события
Бит, байт, Кбайт и т.д.
Семантическая
Тезаурус
Технические показатели
Пакет прикладных программ, персональный компьютер, компьютерные сети и т.д.
мощность, производительность, надежность
Прагматическая
Ценность использования
Емкость памяти, производительность компьютера, скорость передачи данных и т.д.
Денежное выражение,
Время обработки информации и принятия решений
Таблица 1. Единицы измерения информации
Понятие системы счисления, виды систем счисления
На ранних ступенях развития общества люди почти не умели считать. Они отличали друг от друга совокупности двух и трех предметов; всякая совокупность, содержавшая большее число предметов, объединялась в понятии «много». Это был еще не счет, а лишь его зародыш.
Впоследствии способность различать друг от друга небольшие совокупности развивалась; возникли слова для обозначений понятий «четыре», «пять», «шесть», «семь».
С усложнением хозяйственной деятельности людей понадобилось вести счет в более обширных пределах. Для этого человек пользовался окружавшими его предметами, как инструментами счета: он делал зарубки на палках и на деревьях, завязывал узлы на веревках, складывал камешки в кучки и т.п. Такой вид счета носит название унарной системы счисления, т.е. система счисления, в которой для записи числа применяется только один вид знаков. Это удобно, так как сразу визуально определяется количество знаков и сопоставляется с количеством предметов, которые эти знаки обозначают
Особо важную роль играл природный инструмент человека - его пальцы. Этот инструмент не мог длительно хранить результат счета, но зато всегда был «под рукой» и отличался большой подвижностью. Поэтому, вполне естественно, что вновь возникавшие названия «больших» чисел часто строились на основе числа 10 - по количеству пальцев на руках; у некоторых народов возникали также названия чисел на основе числа 5 - по количеству пальцев на одной руке или на основе числа 20 - по количеству пальцев на руках и ногах.
На современном этапе границы счета определены термином «бесконечность», который не обозначает какое либо конкретное число.
Десятичная система счисления
В современном русском языке, а также в языках других народов названия всех чисел до миллиона составляются из 37 слов, обозначающих числа 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000 (например, восемьсот пятнадцать тысяч триста девяносто четыре). В свою очередь названия этих 37 чисел, как правило, образованы из названий чисел первого десятка (1, 2, 3, 4, 5, 6, 7, 8, 9) и чисел 10, 100, 1000 (например, 18 = восемь на десять, 30 = тридесять и т.д.). В основе этого словообразования лежит число десять, и поэтому наша система наименований называется десятичной системой счисления.
Древнегреческая нумерация
В древнейшее время в Греции была распространена т.н. аттическая нумерация. Числа 1, 2, 3, 4 обозначались черточками , ,,. Число 5 записывалось знаком (древнее начертание буквы «пи», с которой начинается слово «пенте» - пять); числа 6, 7, 8, 9 обозначались , , , . Число 10 обозначалось (начальной буквой слова «дека» - десять). Числа 100, 1000 и 10000 обозначались , , . Числа 50, 500, 5000 обозначались комбинациями знаков 5 и 10, 5 и 100, 5 и 1000. Общую запись чисел в аттической нумерации иллюстрирует пример 2.
В третьем веке до н.э. аттическая нумерация была вытеснена так называемой ионийской системой. В ней числа 1 - 9 обозначались первыми девятью буквами алфавита; числа 10, 20, 30, … , 90 - следующими девятью буквами; числа 100, 200, … , 900 - последними девятью буквами.
Таблица 2 Обозначение чисел в ионийской системе нумерацииОбозначение
Название
Значение
Обозначение
Название
Значение
Обозначение
Название
Значение
Альфа
1
Йота
10
Ро
100
Бета
2
Каппа
20
Сигма
200
Гамма
3
Лямбда
30
Тау
300
Дельта
4
Мю
40
Ипсилон
400
Эпсилон
5
Ню
50
Фи
500
Фауб
6
Кси
60
Хи
600
Дзета
7
Омикрон
70
Пси
700
Эта
8
Пи
80
Омега
800
Тэта
9
Коппа
90
Сампи
900
Пример 2. Запись чисел в аттической системе счисления
-
,
,
,
.
Пример 3 Запись чисел в ионийской системе счисления
-
,
,
,
,
.
Такую же алфавитную нумерацию имели в древности евреи, арабы и многие другие народы Ближнего Востока.
Славянская нумерация
Южные и восточные славянские народы для записи чисел пользовались алфавитной нумерацией. У одних славянских народов числовые значения букв установились в порядке славянского алфавита, у других же (в том числе у русских) роль цифр играли не все буквы, а только те, которые имеются в греческом алфавите. Над буквой, обозначавшей цифру, ставился специальный значок: («титло»).
В России славянская нумерация сохранилась до конца XVII века. При Петре I возобладала так называемая «арабская нумерация», которой мы пользуемся и сейчас. Славянская нумерация сохранялась только в богослужебных книгах. В таблице 3 приведены славянские цифры.
При записи чисел, больших 10, цифры писались слева направо в порядке убывания десятичных разрядов (однако иногда для чисел от 11 до 19 единицы записывались ранее десяти). Для обозначения тысяч перед числом их (слева внизу) ставился особый знак .
Пример 4 иллюстрирует написание чисел в славянской системе нумерации.
Таблица 3 Обозначение чисел в древнеславянской системе нумерацииОбозначение
Название
Значение
Обозначение
Название
Значение
Обозначение
Название
Значение
Аз
1
И
10
Рцы
100
Веди
2
Како
20
Слово
200
Глаголь
3
Люди
30
Твердо
300
Добро
4
Мыслите
40
Ук
400
Есть
5
Наш
50
Ферт
500
Зело
6
Кси
60
Хер
600
Земля
7
Он
70
Пси
700
Иже
8
Покой
80
Омега
800
Фита
9
Червь
90
Цы
900
Пример 4 Запись чисел в древнеславянской системе счисления
-
,
,
,
.
Пример 5 Запись чисел римскими цифрами
-
,
,
,
.
Римская нумерация
Древние римляне пользовались нумерацией, которая сохраняется до настоящего времени под именем «римской нумерации». Мы пользуемся ей для обозначения веков, юбилейных дат, наименования съездов и конференций, для нумерации глав книги или строф стихотворения.
В позднейшем своем виде римские цифры выглядят так: , , , , , , .
В римской нумерации явственно сказываются следы пятиричной системы счисления. В языке же римлян (латинском) никаких следов пятиричной системы нет. Значит, эти цифры были заимствованы римлянами у другого народа (предположительно у этрусков).
Все целые числа (до 5000) записываются с помощью повторения вышеприведенных цифр. При этом, если большая цифра стоит перед меньшей, то они складываются, если же меньшая стоит перед большей (в этом случае она не может повторяться), то меньшая вычитается из большей. Подряд одна и та же цифра ставится не более трех раз.
Основные понятия и определения
Выше мы говорили о системах счисления, не вдаваясь в подробности этого понятия. Каково же научное определение системы счисления?
Системой счисления называют систему приемов и правил, позволяющих устанавливать взаимно-однозначное соответствие между любым числом и его представлением в виде совокупности конечного числа символов. Множество символов, используемых для такого представления, называют цифрами.
В зависимости от способа изображения чисел с помощью цифр системы счисления делятся на позиционные и непозиционные.
В непозиционных системах любое число определяется как некоторая функция от численных значений совокупности цифр, представляющих это число. Цифры в непозиционных системах счисления соответствуют некоторым фиксированным числам. Пример непозиционной системы - рассмотренная ранее римская система счисления. Дpевние египтяне пpименяли систему счисления, состоящую из набоpа символов, изобpажавших pаспpостpаненные пpедметы быта. Совокупность этих символов обозначала число. Расположение их в числе не имело значения, отсюда и появилось название.
Исторически первыми системами счисления были именно непозиционные системы. Одним из основных недостатков является трудность записи больших чисел. Запись больших чисел в таких системах либо очень громоздка, либо алфавит системы чрезвычайно велик.
В вычислительной технике непозиционные системы не применяются.
Систему счисления называют позиционной, если одна и та же цифра может принимать различные численные значения в зависимости от номера разряда этой цифры в совокупности цифр, представляющих заданное число. Пример такой системы - арабская десятичная система счисления.
Количества и количественные составляющие, существующие реально могут отображаться различными способами. В общем случае в позиционной системе счисления число N может быть представлено как:
,
- основание системы счисления (целое положительное число, равное числу цифр в данной системе);
- любые цифры из интервала от нуля до .
Основание позиционной системы счисления определяет ее название. В вычислительной технике применяются двоичная, восьмеричная, десятичная и шестнадцатеричная системы. В дальнейшем, чтобы явно указать используемую систему счисления, будем заключать число в скобки и в нижнем индексе указывать основание системы счисления.
Каждой позиции в числе соответствует позиционный (разрядный) коэффициент или вес. Покажем это на примере десятичного числа:
Пример 4, Способ образования десятичного числа
Для десятичной системы соответствия между позицией и весом следующее:
(1)
в общем случае:
(2)
В настоящее время позиционные системы счисления более широко распространены, чем непозиционные. Это объясняется тем, что они позволяют записывать большие числа с помощью сравнительно небольшого числа знаков. Еще более важное преимущество позиционных систем - это простота и легкость выполнения арифметических операций над числами, записанными в этих системах.
Вычислительные машины в принципе могут быть построены в любой системе счисления. Но столь привычная для нас десятичная система окажется крайне неудобной. Если в механических вычислительных устройствах, использующих десятичную систему, достаточно просто применить элемент со множеством состояний (колесо с десятью зубьями), то в электронных машинах надо было бы иметь 10 различных потенциалов в цепях.
Наиболее удобной для построения ЭВМ оказалась двоичная система счисления, т.е. система счисления, в которой используются только две цифры: 0 и 1, т.к. с технической точки зрения создать устройство с двумя состояниями проще, также упрощается различение этих состояний.
Для представления этих состояний в цифровых системах достаточно иметь электронные схемы, которые могут принимать два состояния, четко различающиеся значением какой-либо электрической величины - потенциала или тока. Одному из значений этой величины соответствует цифра 0, другому - 1. Относительная простота создания электронных схем с двумя электрическими состояниями и привела к тому, что двоичное представление чисел доминирует в современной цифровой технике. При этом 0 обычно представляется низким уровнем потенциала, а 1 - высоким уровнем. Такой способ представления называется положительной логикой.
Перевод чисел из одной системы счисления в другую
Системы счисления, используемые в компьютерах.
Таблица 4.Таблица соответствия систем счисления.
Двоичная
Восьмеричная
Шестнадцатеричная
0
0
0
0
1
1
1
1
2
10
2
2
3
11
3
3
4
100
4
4
5
101
5
5
6
110
6
6
7
111
7
7
8
1000
10
8
9
1001
11
9
10
1010
12
А
11
1011
13
В
12
1100
14
С
13
1101
15
D
14
1110
16
Е
15
1111
17
F
16
10000
20
10
17
10001
21
11
…
…
…
…
26
11010
32
1А
Двоичная система счисления. Для записи чисел используются только две цифры - 0 и 1. Выбор двоичной системы объясняется тем, что электронные элементы, из которых строятся ЭВМ, могут находиться только в двух хорошо различимых состояниях. По существу эти элементы представляют собой выключатели. Как известно выключатель либо включен, либо выключен. Третьего не дано. Одно из состояний обозначается цифрой 1, другое - 0.
Благодаря таким особенностям двоичная система стала стандартом при построении ЭВМ.
Восьмеричная система счисления. Для записи чисел используется восемь чисел 0,1,2,3,4,5,6,7.
Шестнадцатеричная система счисления. Для записи чисел в шестнадцатеричной системе необходимо располагать уже шестнадцатью символами, используемыми как цифры. В качестве первых десяти используются те же, что и в десятичной системе. Для обозначения остальных шести цифр (в десятичной они соответствуют числам 10,11,12,13,14,15) используются буквы латинского алфавита - A,B,C,D,E,F.
Перевод целых чисел из десятичной системы счисления в другую.
Правило перевода целых чисел из десятичной системы счисления в систему с основанием q:
-
Последовательно выполнять деление исходного числа и получаемых частных на q до тех пор, пока не получим частное, меньшее делителя.
-
Полученные при таком делении остатки - цифры числа в системе счисления q - записать в обратном порядке (снизу вверх).
Пример 5. Перевести 2610 в двоичную систему счисления.
Решение:
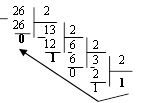
Ответ: 2610=110102
Пример 6. Перевести 24110 в восьмиричную систему счисления. А10→А8
Решение:
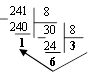
Ответ: 24110=3618
Пример 7. Перевести 362710 в восьмиричную систему счисления. А10→А8
Решение:
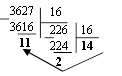
Т.к. в шестнадцатеричной системе счисления 14 - Е, а 11 - В, то получаем ответ Е2В16.
Перевод дробных чисел из десятичной системы счисления в другую.
Правило перевода дробных чисел из десятичной системы счисления в систему с основанием q:
-
Последовательно выполнять умножение исходного числа и получаемых дробные части на q до тех пор, пока дробная часть не станет равна нулю или не достигнем требуемую точность.
-
Полученные при таком умножении целые части - числа в системе счисления q - записать в прямом порядке (сверху вниз).
Пример 8. Перевести 0,562510 в двоичную систему счисления. А10→А2
Решение:
Ответ: 0,562510=0,10012
Пример 9. Перевести 0,562510 восьмеричную систему счисления. А10→А8
Решение:
Ответ: 0,562510=0,528
Пример 10. Перевести 0,66510 в двоичную систему счисления. А10→А2
Решение:
Процесс умножения может продолжаться до бесконечности. Тогда его прерывают на некотором шаге, когда считают, что получена требуемая точность представления числа
Ответ: 0,66510=0,100012
Перевод произвольных чисел из десятичной системы счисления в другую.
Перевод произвольных чисел, то есть чисел, содержащих целую и дробную части, осуществляют в два этапа. Отдельно переводится целая часть, отдельно - дробная. В итоговой записи полученного числа целая часть отделяется от дробной запятой.
Перевод чисел из любой системы счисления в десятичную.
Правило Для того чтобы число из любой системы счисления перевести в десятичную систему счисления, необходимо его представить в развернутом виде и произвести вычисления.
Пример 11. Перевести число 1101102 из двоичной системы счисления в десятичную.
Решение:
5 4 3 2 1 0
1 1 0 1 1 0 2 = 1*25 + 1*24 + 0*23+1*22+1*21+0*20 =32+16+4+2=5410
Ответ: 1101102 = 5410
Пример 12. Перевести число 101,012 из двоичной системы счисления в десятичную.
Решение:
2 1 0 -1 -2
1 0 1,0 1 2 = 1*22 + 0*21 + 1*20+0*2-1+1*2-2 =4+0+1+0+0,25=5,2510
Ответ: 101,012 = 5,2510
Пример 13. Перевести число 1221003 из троичной системы счисления в десятичную.
Решение:
4 3 2 1 0
1 2 2 0 1 3=1*34 + 2*33 + 2*32 + 0*31 + 1*30 = 81+54+18+1 = 15410
Ответ: 122013 = 15410
Пример 14. Перевести число 1637 из семеричной системы счисления в десятичную.
Решение:
1637 = 1*72 + 6*71 + 3*70 = 49+42+3= 9410.
Ответ: 1637 = 9410.
Пример 15. Перевести число 234,68 из восьмеричной системы в десятичную:
Решение:
2 1 0 -1
2 3 4, 68 = 2*82 +3*81 + 4*80 +6*8-1= 2*64+3*8+4+6*0,125= 128+24+4+0,75 =156,7510
Ответ: 234,68 = 156,7510.
Пример 16. Перевести число 2Е16 в десятичную систему счисления.
Решение:
2 1
2 Е16 = 2*161 +14*160 = 32 +14 = 4610.
Ответ: 2Е16 = 4610.
Перевод чисел из двоичной системы счисления в восьмеричную и шестнадцатеричную системы счисления.
Перевод целых чисел.
Правило Чтобы перевести целое двоичное число в восьмеричную (8=23) систему счисления необходимо:
-
разбить данное число справа налево на группы по 3 цифры в каждой;
-
рассмотреть каждую группу и записать ее соответствующей цифрой восьмеричной системы счисления.
Пример 17. Перевести число 111010102 в восьмеричную систему счисления.
Решение:
11101010
3 5 2
Ответ: 111010102 = 3528
Правило Чтобы перевести целое двоичное число в шестнадцатеричную (16=24) систему счисления необходимо:
-
разбить данное число справа налево на группы по 4 цифры в каждой;
-
рассмотреть каждую группу и записать ее соответствующей цифрой шестнадцатеричной системы счисления.
Пример 18. Перевести число 111000102 в шестнадцатеричную систему счисления.
Решение:
11100010
Е 2
Ответ: 111000102 = Е216
Перевод дробных чисел.
Правило Чтобы перевести дробное двоичное число в восьмеричную (шестнадцатеричную) систему счисления необходимо:
-
разбить данное число, начиная от запятой влево целую часть и вправо дробную часть на группы по 3 (4) цифры в каждой;
-
рассмотреть каждую группу и записать ее соответствующей цифрой восьмеричной (шестнадцатеричной)системы счисления.
Пример 19. Перевести число 0,101100001112 в шестнадцатеричную систему счисления.
Решение:
0,10110000111
В 0 7
Ответ: 0,101100001112 = В0716
Приме 20. Перевести число 111100001,01112 в восьмеричную систему счисления.
Решение:
111100001,0111
7 4 1 3 1
Ответ: 111100001,01112= 741,318
Перевод чисел из восьмеричной и шестнадцатеричной систем счисления в двоичную систему счисления.
Правило Для того, чтобы восьмеричное (шестнадцатеричное) число перевести в двоичную систему счисления, необходимо каждую цифру этого числа заменить соответствующим числом, состоящим из 3 (4) цифр двоичной системы счисления.
Пример 21. Перевести число 5288 перевести в двоичную систему счисления.
Решение:
5 2 3
101 010 011
Ответ: 5288 = 1010100112
Пример 22. Перевести число 4ВА35,1С216 перевести в двоичную систему счисления.
Решение:
4 В А 3 5 , 1 С 2
100 1011 101000110101 0001 1100 0010
Ответ: 4ВА35,1С216 = 10010111010001101010001 110000102
Арифметические операции в системах счисления
Арифметические операции во всех позиционных системах счисления выполняются по одним и тем же хорошо известным правилам.
Правила выполнения арифметических операций в десятичной системе хорошо известны - это сложение, вычитание, умножение столбиком и деление уголком. Эти правила применимы и ко всем другим позиционным системам счисления. Только таблицами сложения и умножения надо пользоваться особыми для каждой системы.
Таблицы сложения в любой позиционной системе счисления легко составить, используя правило счета:
Если сумма складываемых цифр больше или равна основанию системы счисления, то единица переносится в следующий слева разряд.
Таблица 5. Сложение в двоичной системе.
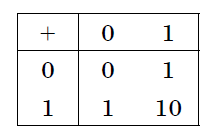
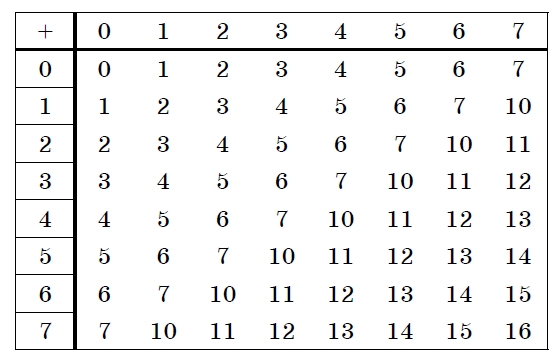
Таблица 6. Сложение в восьмеричной системе.
Пример 23. Сложим числа 15 и 6 в различных системах счисления.
Решение.
Переведем числа 15 и 6в двоичную и восьмеричную системы счисления и выполним сложение, используя таблицы сложения (см. выше).
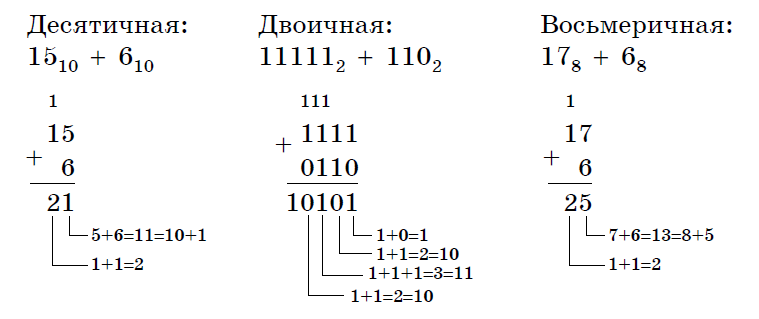
Ответ: 15+6=2110=101012=258
Пример 24. Вычислим сумму чисел 438 и 5616. Результат представим в восьмеричной системе счисления.
Решение.
Переведем число 5616 в восьмеричную систему счисления, используя поразрядный способ перевода разложением на тэтрады и триады:
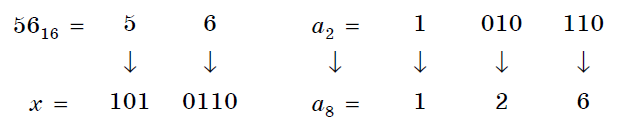
Пользуясь правилами сложения в восьмеричной системе счисления, получаем:
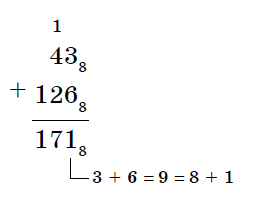
Ответ: 438 + 5616 = 1718
Вычитание осуществляется по тем же правилам, что и в десятичной системе счисления.
При вычитании из меньшего числа большего производится заем из старшего разряда.
Пример 25.
Вычислим разность X−Y двоичных чисел, если X=10101002 и Y=10000102. Результат представим в двоичном виде.
Решение:
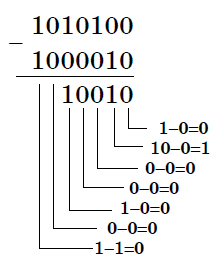
Ответ: 100102
Выполняя умножение многозначных чисел в различных позиционных системах счисления, можно использовать обычный алгоритм перемножения чисел в столбик, но при этом результаты перемножения и сложения однозначных чисел необходимо заимствовать из соответствующих рассматриваемой системе таблиц умножения и сложения.
Таблица 7. Умножение в двоичной системе.
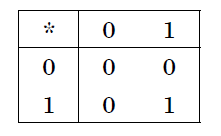
Таблица 8. Умножение в восьмеричной системе.
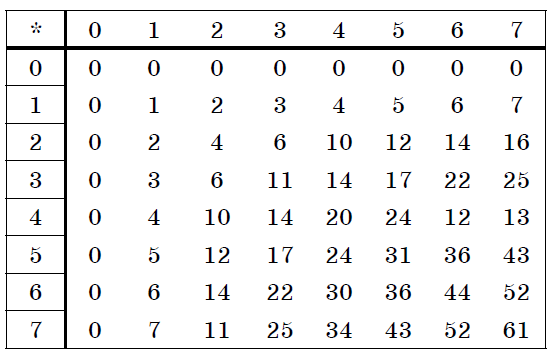
Умножение многоразрядных чисел в различных позиционных системах счисления происходит по обычной схеме, применяемой в десятичной системе счисления, с последовательным умножением множимого на очередную цифру множителя.
Пример 26.
Перемножим числа 15 и 12.

Ответ: 15⋅12=18010=101101002=2648
Операция деления выполняется по алгоритму, подобному алгоритму выполнения операции деления в десятичной системе счисления. Следует только грамотно пользоваться теми цифрами, которые входят в алфавит используемой системы счисления.
Понятие количества информации. Единицы измерения информации.
Какое количество информации содержится, к примеру, в тексте романа "Война и мир", во фресках Рафаэля или в генетическом коде человека? Ответа на эти вопросы наука не даёт и, по всей вероятности, даст не скоро. А возможно ли объективно измерить количество информации? Важнейшим результатом теории информации является следующий вывод:
В определенных, весьма широких условиях можно пренебречь качественными особенностями информации, выразить её количество числом, а также сравнить количество информации, содержащейся в различных группах данных.
В настоящее время получили распространение подходы к определению понятия "количество информации", основанные на том, что информацию, содержащуюся в сообщении, можно нестрого трактовать в смысле её новизны или, иначе, уменьшения неопределённости наших знаний об объекте. Эти подходы используют математические понятия вероятности и логарифма.
Объём информации можно представлять как логарифм[2]количества возможных состояний.
Наименьшее целое число, логарифм которого положителен - это 2. Соответствующая ему единица - бит - является основой исчисления ин-формации в цифровой технике.
Единица, соответствующая числу 3 (трит) равна log23≈1,585 бита, числу 10 (хартли) - log210≈3.322 бита.
Такая единица как нат (nat), соответствующая натуральному логарифму применяется в инженерных и научных расчётах. В вычислительной технике она практически не применяется, так как основание натуральных логарифмов не является целым числом.
Единицы, производные от бита
Целые количества бит отвечают количеству состояний, равному степеням двойки.
Особое название имеет 4 бита - ниббл (полубайт, тетрада, четыре двоичных разряда), которые вмещают в себя количество информации, со-держащейся в одной шестнадцатеричной цифре.
Байт
Следующей по порядку популярной единицей информации является 8 бит, или байт (о терминологических тонкостях написано ниже). Именно к байту (а не к биту) непосредственно приводятся все большие объёмы информации, исчисляемые в компьютерных технологиях.
Такие величины как машинное слово и т. п., составляющие несколько байт, в качестве единиц измерения почти никогда не используются.
Килобайт
Для измерения больших количеств байтов служат единицы «килобайт» = [1024] байт и «Кбайт»[3] (кибибайт, kibibyte) = 1024 байт (о путанице десятичных и двоичных единиц и терминов см. ниже). Такой порядок величин имеют, например:
-
Сектор диска обычно равен 512 байтам то есть половине килобайта, хотя для некоторых устройств может быть равен одному или двум кибибайт.
-
Классический размер «блока» в файловых систе-мах UNIX равен одному Кбайт (1024 байт).
-
«Страница памяти» в процессорах x86 (начиная с моде-ли Intel 80386) имеет размер 4096 байт, то есть 4 Кбайт.
Объём информации, получаемой при считывании дискеты «3,5″ высокой плотности» равен 1440 Кбайт (ровно); другие форматы также исчисляются целым числом Кбайт.
Мегабайт
Единицы «мегабайт» = 1024 килобайт = [1048576] байт и «Мбайт» (мебибайт, mebibyte) = 1024 Кбайт = 1 048 576 байт применяются для измерения объёмов носителей информации.
Объём адресного пространства процессора Intel 8086 был равен 1 Мбайт.
Оперативную память и ёмкость CD-ROM меряют двоичными единицами (мебибайтами, хотя их так обычно не называют), но для объёма НЖМД десятичные мегабайты были более популярны.
Современные жёсткие диски имеют объёмы, выражаемые в этих единицах минимум шестизначными числами, поэтому для них применяются гигабайты.
Следующей по порядку популярной единицей информации является 8 бит, или байт (о терминологических тонкостях написано ниже). Именно к байту (а не к биту) непосредственно приводятся все большие объёмы информации, исчисляемые в компьютерных технологиях.
Такие величины как машинное слово и т. п., составляющие не-сколько байт, в качестве единиц измерения почти никогда не используются.
Гигабайт
Единицы «гигабайт» = 1024 мегабайт = [1048576] килобайт = [1073741824] байт и «Гбайт» (гибибайт, gibibyte) = 1024 Мбайт = 230байт измеряют объём больших носителей информации, например жёстких дисков. Разница между двоичной и десятичной единицами уже превышает 7 %.
Размер 32-битного адресного пространства равен 4 Гбайт ≈ 4,295 Мбайт. Такой же порядок имеют размер DVD-ROM и современных носителей на флэш-памяти. Размеры жёстких дисков уже достигают сотен и тысяч гигабайт.
Для исчисления ещё больших объёмов информации имеются единицы терабайт и тебибайт (1012 и 240 байт соответствен-но),петабайт и пебибайт (1015 и 250 байт соответственно) и т. д.
Байт определяется для конкретного компьютера как минимальный шаг адресации памяти, который на старых машинах не обязательно был равен 8 битам (а память не обязательно состоит из битов - см., например: троичный компьютер). В современной традиции, байт часто считают равным восьми битам.
В таких обозначениях как байт (русское) или B (английское) под байт (B) подразумевается именно 8 бит, хотя сам термин «байт» не вполне корректен с точки зрения теории.
Во французском языке используются обозначения o, Ko, Mo и т. д. (от слова octet) дабы подчеркнуть, что речь идёт именно о 8 битах.
Долгое время разнице между множителями 1000 и 1024 старались не придавать большого значения. Во избежание недоразумений следует чётко понимать различие между:
-
двоичными кратными единицами, обозначаемыми соглас-но ГОСТ 8.417-2002 как «Кбайт», «Мбайт», «Гбайт» и т. д. (два в степенях кратных десяти);
-
единицами килобайт, мегабайт, гигабайт и т. д., понимаемыми как научные термины (десять в степенях, кратных трём),эти единицы по определению равны, соответственно, 103, 106, 109 байтам и т. д.
В качестве терминов для «Кбайт», «Мбайт», «Гбайт» и т. д. МЭК предлагает «кибибайт», «мебибайт», «гибибайт» и т. д., однако эти термины критикуются за непроизносимость и не встречаются в устной речи.
В различных областях информатики предпочтения в употреблении десятичных и двоичных единиц тоже различны. Причём, хотя со времени стандартизации терминологии и обозначений прошло уже несколько лет, далеко не везде стремятся прояснить точное значение используемых единиц.
В английском языке для «киби»=1024 иногда используют прописную букву K, дабы подчеркнуть отличие от обозначаемой строчной бук-вой приставки СИ кило. Однако, такое обозначение не опирается на авторитетный стандарт, в отличие от российского ГОСТа касательно «Кбайт».
Формула Хартли. Методы и средства определения количества информации.
Американский инженер Р. Хартли в 1928 г. процесс получения информации рассматривал как выбор одного сообщения из конечного наперёд заданного множества из N равновероятных сообщений, а количество информации I, содержащееся в выбранном сообщении, определял как двоичный логарифм N.
Формула Хартли:
I = log2N
Допустим, нужно угадать одно число из набора чисел от единицы до ста. По формуле Хартли можно вычислить, какое количество информации для этого требуется: I = log2100 = 6,644. Таким образом, сообщение о верно угаданном числе содержит количество информации, приблизительно равное 6,644 единицы информации.
Задача 1.
Шарик находится в одной из трех урн: А, В или С. Определить сколько бит информации содержит сообщение о том, что он находится в урне В.
Решение.
Такое сообщение содержит I = log2 3 = 1,585 бита информации.
Приведем другие примеры равновероятных сообщений:
-
При бросании монеты: "выпала решка", "выпал орел";
-
На странице книги: "количество букв чётное", "количество букв нечётное".
Определим теперь, являются ли равновероятными сообщения "первой выйдет из дверей здания женщина" и "первым выйдет из дверей здания мужчина". Однозначно ответить на этот вопрос нельзя. Все зависит от того, о каком именно здании идет речь. Если это, например, станция метро, то вероятность выйти из дверей первым одинакова для мужчины и женщины, а если это военная казарма, то для мужчины эта вероятность значительно выше, чем для женщины.
В 1948 г. американский инженер и математик К Шеннон предложил формулу для вычисления количества информации для событий с различными вероятностями.
Если
I - количество информации,
К - количество возможных событий,
рi - вероятности отдельных событий,
то количество информации для событий с различными вероятностями можно определить по формуле:
, где i принимает значения от 1 до К.
Формулу Хартли теперь можно рассматривать как частный случай формулы Шеннона:
При равновероятных событиях получаемое количество информации максимально.
Задача 2.
Определить количество информации, получаемое при реализации одного из событий, если бросают
-
несимметричную четырехгранную пирамидку;
-
симметричную и однородную четырехгранную пирамидку.
Решение.
-
Будем бросать несимметричную четырехгранную пирамидку.
Вероятность отдельных событий будет такова:
р1 = 1 / 2,
р2 = 1 / 4,
р3 = 1 / 8,
р4 = 1 / 8,
тогда количество информации, получаемой после реализации одного из этих событий, рассчитывается по формуле:
(бит)
-
Теперь рассчитаем количество информации, которое получится при бросании симметричной и однородной четырехгранной пирамидки:
(бит)
Формула Шеннона:
, где -вероятность того, что именно i-е сообщение выделено в наборе из N сообщений.
Легко заметить, что если вероятности равны, то каждая из них равна 1 / N, и формула Шеннона превращается в формулу Хартли.
Помимо двух рассмотренных подходов к определению количества информации, существуют и другие. Важно помнить, что любые теоретические результаты применимы лишь к определённому кругу случаев, очерченному первоначальными допущениями.
В качестве единицы информации Клод Шеннон предложил принять один бит (англ. bit - binary digit - двоичная цифра).
Бит в теории информации - количество информации, необходимое для различения двух равновероятных сообщений (типа "орел"-"решка", "чет"-"нечет" и т.п.).
В вычислительной технике битом называют наименьшую "порцию" памяти компьютера, необходимую для хранения одного из двух знаков "0" и "1", используемых для внутримашинного представления данных и команд.
Бит - слишком мелкая единица измерения. На практике чаще применяется более крупная единица - байт, равная восьми битам. Именно восемь битов требуется для того, чтобы закодировать любой из 256 символов алфавита клавиатуры компьютера (256=28).
Широко используются также ещё более крупные производные единицы информации:
1 Килобайт (Кбайт) = 1024 байт = 210байт
1 Мегабайт (Мбайт) = 1024 Кбайт = 220 байт,
1 Гигабайт (Гбайт) = 1024 Мбайт = 230 байт.
В последнее время в связи с увеличением объёмов обрабатываемой информации входят в употребление такие производные единицы, как:
1 Терабайт (Тбайт) = 1024 Гбайт = 240 байт,
1 Петабайт (Пбайт) = 1024 Тбайт = 250 байт.
За единицу информации можно было бы выбрать количество информации, необходимое для различения, например, десяти равновероятных сообщений. Это будет не двоичная (бит), а десятичная (дит) единица информации.
Алфавитный подход к определению информацию.
При определении количества информации на основе уменьшения неопределенности наших знаний мы рассматриваем информацию с точки зрения содержания, ее понятности и новизны для человека. С этой точки зрения в опыте по бросанию монеты одинаковое количество информации содержится и в зрительном образе упавшей монеты, и в коротком сообщении «Орел», и в длинной фразе «Монета упала на поверхность земли той стороной вверх, на которой изображен орел».
Однако при хранении и передаче информации с помощью технических устройств целесообразно отвлечься от содержания информации и рассматривать ее как последовательность знаков (букв, цифр, кодов цветов точек изображения и так далее).
Набор символов знаковой системы (алфавит) можно рассматривать как различные возможные состояния (события). Тогда, если считать, что появление символов в сообщении равновероятно, по формуле N=2I можно рассчитать, какое количество информации несет каждый символ.
Так, в русском алфавите, если не использовать букву ё, количество событий (букв) будет равно 32. Тогда:
32=2I
откуда I=5 битов.
Каждый символ несет 5 битов информации (его информационная емкость равна 5 битов). Количество информации в сообщении можно подсчитать, умножив количество информации, которое несет один символ, на количество символов.
Количество информации, которое содержит сообщение, закодированное с помощью знаковой системы, равно количеству информации, которое несет один знак, умноженному на количество знаков.
Задача 3.
Книга, набранная с помощью компьютера, содержит 150 страниц, на каждой странице - 40 строк, в каждой строке - 60 символов. Каков объем информации в книге?
Решение.
40 60 150 =360000 символов в книге = 360000 байт.
360000 байт = = 351,5625 Кб = = 0,34332275Мб.
Объем книги 0,34 Мб.
Задача 4.
Сколько килобайт составляет сообщение, содержащее 12288 бит?
Решение.
12288 / 8 / 1024 = 1,5 Кб.
Задача 5.
Можно ли уместить на одну дискету книгу, имеющую 432 страницы, причем на каждой странице этой книги 46 строк, а в каждой строке 62 символа?
Решение.
46 62 432 =1 232 064 символов в книге = 1 232 064 байт.
1 232 064 байт = 1,17 Мб.
Емкость дискеты 1,44 Мб, значит, книга может поместиться на одну дискету.
Задача 6.
Сообщение, записанное буквами из 64-символьного алфавита, содержит 20 символов. Какой объем информации оно несет?
Решение.
20i = 64, i = 6 бит - количество информации, которое несет каждый символ, 20 6 = 120 бит = 15 байт.
Задача 7.
Одно племя имеет 32-символьный алфавит, а второе племя - 64-символьный алфавит. Вожди племен обменялись письмами. Письмо первого племени содержало 80 символов, а письмо второго племени - 70 символов. Сравните объем информации, содержащийся в письмах.
Решение.
Первое племя: 2i = 32, i = 5 бит - количество информации, которое несет каждый символ, 5 80 = 400 бит.
Второе племя: 2i = 64, i = 6 бит - количество информации, которое несет каждый символ, 6 70 = 420 бит.
Значит, письмо второго племени содержит больше информации.
Задача 8.
Информационное сообщение объемом 1,5 Кб содержит 3072 символа. Сколько символов содержит алфавит, при помощи которого было записано это сообщение?
Решение.
I = 1,5 Кб = 1,5 1024 = 1536 байта = 1536 8 = 12288 бит.
i = = = 4 бита.
N = 2i = 24 = 16 символов.
Задача 9.
Объем сообщения, содержащего 2048 символов, составил Мб. Каков размер алфавита, с помощью которого записано сообщение?
Решение.
I = Мб = 1024 1024 8 = 16384 бит.
i = = = 8 бит.
N = 2i = 28 = 256 символов.
Задача 8.
Сколько символов содержит сообщение, записанное с помощью 16-символьного алфавита, если объем этого сообщения составил Мб.
Решение.
I = Мб = 1024 1024 8 = 524 288 бит.
N = 16 = 2i, i = 4 бита.
K = = = 131 072 символа.
Задача 9.
Для записи сообщения использовался 64-символьный алфавит. Каждая страница содержит 30 строк. Все сообщение содержит 8775 байт информации и занимает 6 страниц. Сколько символов в строке?
Решение.
I = 8775 байт = 8775 8 = 70 200 бит.
N = 64 = 2i , i = 6 бит.
Объем информации одной страницы книги =
= = = 11 700бит.
Количество символов в строке: 11 700 бит / 6 бит / 30 строк = 65 символов.
Задача 10.
ДНК человека (генетический код) можно представить себе как некоторое слово в четырехбуквенном алфавите, где каждой буквой помечается звено цепи ДНК (нуклеотид). Сколько информации в битах содержит цепочка ДНК человека, содержащая примерно 1,51023 нуклеотидов?
Решение.
N = 4 = 2i , i = 2 бита.
I = K i = 1,5 1023 2 = 3 1023 бита.
Данные и их кодирование. Принципы кодирования и декодирования.
Представление информации происходит в различных формах в процессе восприятия окружающей среды живыми организмами и человеком, в процессах обмена информацией между человеком и человеком, человеком и компьютером, компьютером и компьютером и так далее. Преобразование информации из одной формы представления (знаковой системы) в другую называется кодированием.
Средством кодирования служит таблица соответствия знаковых систем, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем.
В процессе обмена информацией часто приходится производить операции кодирования и декодирования информации. При вводе знака алфавита в компьютер путем нажатия соответствующей клавиши на клавиатуре происходит кодирование знака, то есть преобразование его в компьютерный код. При выводе знака на экран монитора или принтер происходит обратный процесс - декодирование, когда из компьютерного кода знак преобразуется в его графическое изображение.
Кодирование - это операция преобразования знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы.
Рассмотрим в качестве примера кодирования соответствие цифрового и штрихового кодов товара. Такие коды имеются на каждом товаре и позволяют полностью идентифицировать товар (страну и фирму производителя, тип товара и др.).

Рисунок 2.
Знакам цифрового кода (цифрам) соответствуют группы знаков штрихового кода (узкие и широкие штрихи, а также размеры промежутков между ними) - рис.2. Для человека удобен цифровой код, а для автоматизированного учета - штриховой код, который считывается с помощью узкого светового луча и подвергается последующей обработке в компьютерных бухгалтерских системах учета.
Аналоговый и дискретный способы представления информации.
Человек способен воспринимать и хранить информацию в форме образов (зрительных, звуковых, осязательных, вкусовых и обонятельных). Зрительные образы могут быть сохранены в виде изображений (рисунков, фотографий и так далее), а звуковые - зафиксированы на пластинках, магнитных лентах, лазерных дисках и так далее.
Информация, в том числе графическая и звуковая, может быть представлена в аналоговой или дискретной форме. При аналоговом представлении физическая величина принимает бесконечное множество значений, причем ее значения изменяются непрерывно. При дискретном представлении физическая величина принимает конечное множество значений, причем ее величина изменяется скачкообразно.
Приведем пример аналогового и дискретного представления информации. Положение тела на наклонной плоскости и на лестнице задается значениями координат X и У. При движении тела по наклонной плоскости его координаты могут принимать бесконечное множество непрерывно изменяющихся значений из определенного диапазона, а при движении по лестнице - только определенный набор значений, причем меняющихся скачкообразно.
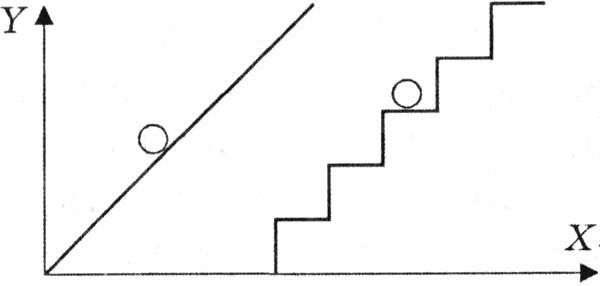
Рисунок 3.
Примером аналогового представления графической информации может служить, например, живописное полотно, цвет которого изменяется непрерывно, а дискретного - изображение, напечатанное с помощью струйного принтера и состоящее из отдельных точек разного цвета. Примером аналогового хранения звуковой информации является виниловая пластинка (звуковая дорожка изменяет свою форму непрерывно), а дискретного - аудиокомпакт-диск (звуковая дорожка которого содержит участки с различной отражающей способностью).
Преобразование графической и звуковой информации из аналоговой формы в дискретную производится путем дискретизации, то есть разбиения непрерывного графического изображения и непрерывного (аналогового) звукового сигнала на отдельные элементы. В процессе дискретизации производится кодирование, то есть присвоение каждому элементу конкретного значения в форме кода.
Дискретизация - это преобразование непрерывных изображений и звука в набор дискретных значений в форме кодов.
Кодирование дискретной и аналоговой информации.
Структурная схема одноканальной системы передачи информации приведена на рис. 4. Информация поступает в систему в форме сообщений. Под сообщением понимают совокупность знаков или первичных сигналов, содержащих информацию. Источник сообщений в общем случае образует совокупность источника информации (исследуемого или наблюдаемого объекта) и первичного преобразователя (датчика, человека-оператора и т.п.), воспринимающего информацию о его состояниях или протекающем в нем процессе. Различают дискретные и непрерывные сообщения.
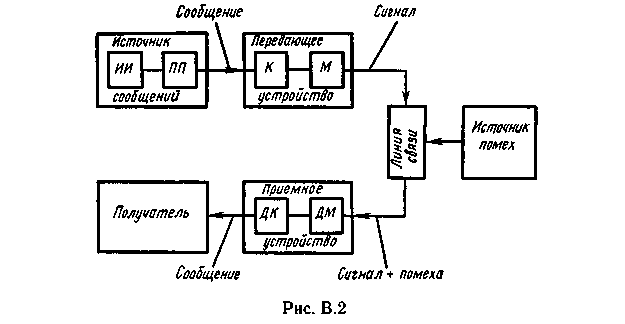
Рисунок 4.
Дискретные сообщения формируются в результате последовательной выдачи источником отдельных элементов - знаков. Множество различных знаков называют алфавитом источника сообщений, а число знаков - объемом алфавита. В частности, знаками могут быть буквы естественного или искусственного языка, удовлетворяющие определенным правилам взаимосвязи. Распространенной разновидностью дискретных сообщений являются данные.
Непрерывные сообщения не разделимы на элементы. Они описываются функциями времени, принимающими непрерывное множество значений. Типичными примерами непрерывных сообщений могут служить речь, телевизионное изображение. В ряде систем связи непрерывные сообщения с целью повышения качества передачи преобразуются в дискретные.
Для передачи сообщения по каналу связи ему необходимо поставить в соответствие определенный сигнал. В информационных системах под сигналом понимают физический процесс, отображающий (несущий) сообщение. Преобразование сообщения в сигнал, удобный для передачи по данному каналу связи, называют кодированием в широком смысле слова. Операцию восстановления сообщения по принятому сигналу называют декодированием.
Так как число возможных дискретных сообщений при неограниченном увеличении времени стремится к бесконечности, а за достаточно большой промежуток времени весьма велико, то ясно, что создать для каждого сообщения свой сигнал практически невозможно. Однако, поскольку дискретные сообщения складываются из знаков, имеется возможность обойтись конечным числом образцовых сигналов, соответствующих отдельным знакам алфавита источника.
Для обеспечения простоты и надежности распознавания образцовых сигналов их число целесообразно сократить до минимума. Поэтому, как правило, прибегают к операции представления исходных знаков в другом алфавите с меньшим числом знаков, называемых символами. При обозначении этой операции используется тот же термин "кодирование", рассматриваемый в узком смысле. Устройство, выполняющее такую операцию, называют кодирующим или кодером К. Так как алфавит символов меньше алфавита знаков, то каждому знаку соответствует некоторая последовательность символов, которую назовем кодовой комбинацией. Число символов в кодовой комбинации называют ее значностью, число ненулевых символов - весом.
Аналогично, для операции сопоставления символов со знаками исходного алфавита используется термин "декодирование". Техническая реализация ее осуществляется декодирующим устройством или декодером ДК. В простейшей системе связи кодирующее, а следовательно, и декодирующее устройство может отсутствовать.
Передающее устройство осуществляет преобразование непрерывных сообщений или знаков в сигналы, удобные для прохождения по конкретной линии связи (либо для хранения в некотором запоминающем устройстве). При этом один или несколько параметров выбранного носителя изменяют в соответствии с передаваемой информацией. Такой процесс называют модуляцией. Он осуществляется модулятором М. Обратное преобразование сигналов в символы производится демодулятором ДМ.
Под линией связи понимают любую физическую среду (воздух, металл, магнитную ленту и т.п.), обеспечивающую поступление сигналов от передающего устройства к приемному. Сигналы на выходе линии связи могут отличаться от переданных вследствие затухания, искажения и воздействия помех. Помехами называют любые мешающие возмущения, как внешние (атмосферные помехи, промышленные помехи), так и внутренние (источником которых является сама аппаратура связи), вызывающие случайные отклонения принятых сигналов от переданных. Эффект воздействия помех на различные блоки системы стараются учесть эквивалентным изменением характеристик линии связи. Поэтому источник помех условно относят к линии связи.
Из смеси сигнала, и помехи приемное устройство выделяет сигнал и посредством декодера восстанавливает Сообщение, которое в общем случае может отличаться от посланного. Меру соответствия принятого сообщения посланному называют верностью передачи. Обеспечение заданной верности передачи сообщений - важнейшая цель системы связи.
Принятое сообщение с выхода системы связи поступает к абоненту-получателю, которому была адресована исходная информация.
Совокупность средств, предназначенных для передачи сообщений, называют каналом связи. Для передачи информации от группы источников, сосредоточенных в одном пункте, к группе получателей, расположенных в другом пункте, часто целесообразно использовать только одну линию связи, организовав на ней требуемое число каналов. Такие системы называют многоканальными.
Кодирование и обработка звуковой информации
Звуковая информация. Звук представляет собой распространяющуюся в воздухе, воде или другой среде волну с непрерывно меняющейся интенсивностью и частотой.
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука (рис. 5).
Человек может воспринимать звук в огромном диапазоне интенсивностей, в котором максимальная интенсивность больше минимальной в 1014 раз (в сто тысяч миллиардов раз). Для измерения громкости звука применяется специальная единица "децибел"(дбл) (табл.8). Уменьшение или увеличение громкости звука на 10 дбл соответствует уменьшению или увеличению интенсивности звука в 10 раз.
Таблица 8. Громкость звука
Громкость в децибелах
Нижний предел чувствительности человеческого уха
0
Шорох листьев
10
Разговор
60
Гудок автомобиля
90
Реактивный двигатель
120
Болевой порог
140
Временная дискретизация звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
Таким образом, непрерывная зависимость громкости звука от времени A(t) заменяется на дискретную последовательность уровней громкости. На графике это выглядит как замена гладкой кривой на последовательность "ступенек" (рис. 6).
Частота дискретизации звука - это количество измерений громкости звука за одну секунду.
Частота дискретизации звука может лежать в диапазоне от 8000 до 48 000 измерений громкости звука за одну секунду.
Глубина кодирования звука. Каждой "ступеньке" присваивается определенное значение уровня громкости звука. Уровни громкости звука можно рассматривать как набор возможных состояний N, для кодирования которых необходимо определенное количество информации I, которое называется глубиной кодирования звука.
Глубина кодирования звука - это количество информации, которое необходимо для кодирования дискретных уровней громкости цифрового звука.
Если известна глубина кодирования, то количество уровней громкости цифрового звука можно рассчитать по формуле N = 2I. Пусть глубина кодирования звука составляет 16 битов, тогда количество уровней громкости звука равно:
N = 2I = 216 = 65 536.
В процессе кодирования каждому уровню громкости звука присваивается свой 16-битовый двоичный код, наименьшему уровню звука будет соответствовать код 0000000000000000, а наибольшему - 1111111111111111.
Качество оцифрованного звука. Чем больше частота и глубина дискретизации звука, тем более качественным будет звучание оцифрованного звука. Самое низкое качество оцифрованного звука, соответствующее качеству телефонной связи, получается при частоте дискретизации 8000 раз в секунду, глубине дискретизации 8 битов и записи одной звуковой дорожки (режим "моно"). Самое высокое качество оцифрованного звука, соответствующее качеству аудио-CD, достигается при частоте дискретизации 48 000 раз в секунду, глубине дискретизации 16 битов и записи двух звуковых дорожек (режим "стерео").
Необходимо помнить, что чем выше качество цифрового звука, тем больше информационный объем звукового файла. Можно оценить информационный объем цифрового стереозвукового файла длительностью звучания 1 секунда при среднем качестве звука (16 битов, 24 000 измерений в секунду). Для этого глубину кодирования необходимо умножить на количество измерений в 1 секунду й умножить на 2 (стереозвук):
16 бит × 24 000 × 2 = 768 000 бит = 96 000 байт = 93,75 Кбайт.
Звуковые редакторы. Звуковые редакторы позволяют не только записывать и воспроизводить звук, но и редактировать его. Оцифрованный звук представляется в звуковых редакторах в наглядной форме, поэтому операции копирования, перемещения и удаления частей звуковой дорожки можно легко осуществлять с помощью мыши. Кроме того, можно накладывать звуковые дорожки друг на друга (микшировать звуки) и применять различные акустические эффекты (эхо, воспроизведение в обратном направлении и др.).
Звуковые редакторы позволяют изменять качество цифрового звука и объем звукового файла путем изменения частоты дискретизации и глубины кодирования. Оцифрованный звук можно сохранять без сжатия в звуковых файлах в универсальном формате WAV или в формате со сжатием МР3.
При сохранении звука в форматах со сжатием отбрасываются "избыточные" для человеческого восприятия звуковые частоты с малой интенсивностью, совпадающие по времени со звуковыми частотами с большой интенсивностью. Применение такого формата позволяет сжимать звуковые файлы в десятки раз, однако приводит к необратимой потере информации (файлы не могут быть восстановлены в первоначальном виде).
Теорема Котельникова и ее применение
Теоре́ма Коте́льникова (в англоязычной литературе - теорема
Найквиста - Шеннона или теорема отсчётов) гласит, что, если
аналоговый сигнал ![]() имеет
ограниченный спектр, то он может быть восстановлен однозначно и
без потерь по своим дискретным отсчётам, взятым с частотой
строго большей удвоенной максимальной частоты спектра
имеет
ограниченный спектр, то он может быть восстановлен однозначно и
без потерь по своим дискретным отсчётам, взятым с частотой
строго большей удвоенной максимальной частоты спектра ![]() :
:
![]()
Такая трактовка рассматривает идеальный случай, когда сигнал начался бесконечно давно и никогда не закончится, а также не имеет во временно́й характеристике точек разрыва. Именно это подразумевает понятие «спектр, ограниченный частотой fc».
Разумеется, реальные сигналы (например, звук на цифровом носителе) не обладают такими свойствами, так как они конечны по времени и, обычно, имеют во временно́й характеристике разрывы. Соответственно, их спектр бесконечен. В таком случае полное восстановление сигнала невозможно и из теоремы Котельникова вытекают 2 следствия:
-
Любой аналоговый сигнал может быть восстановлен с какой угодно точностью по своим дискретным отсчётам, взятым с частотой
f> 2fc, где fc - максимальная частота, которой ограничен спектр реального сигнала.
-
Если максимальная частота в сигнале превышает половину частоты дискретизации, то способа восстановить сигнал из дискретного в аналоговый без искажений не существует.
Говоря шире, теорема Котельникова утверждает, что непрерывный сигнал можно представить в виде интерполяционного ряда
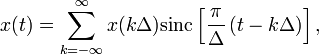
Где - функция sinc. Интервал дискретизации удовлетворяет ограничениям Мгновенные значения данного ряда есть дискретные отсчёты сигнала .
При оцифровке или дискретизации аналогового сигнала X(t) происходит замена непрерывной функции U=U(t) на интервале [t1, t2] ломанной с большим количеством маленьких звеньев (ступенек). Это осуществляется путем развертки по времени оси квантования по величине. Длительность ступенек равна шагу квантования по времени dt=1/f, где f -- частота отсчетов, а их величина кратна шагу квантования по величине dU. Величина каждой ступеньки представляется в двоичном коде, в результате чего получается массив x={x1, x2, ... , xn}
Теорема отсчетов В.А.Котельникова (1933 г.):
Непрерывный сигнал может быть оцифрован и воссоздан без потери информации, если шаг развертки по времени не превышает половину периода максимальной гармоники сигнала: dt<1/2fmax.
Например, для оцифровки речевого сигнала с частотой до 5 кГц, частота отсчетов должна быть не менее 10 кГц.
Теорема квантования по величине:
Для качественной оцифровки и воспроизведения непрерывного сигнала достаточно, чтобы шаг квантования по величине был меньше чувствительности приемного устройства dU.
Если глаз человека (приемник) различает 16 миллионов цветовых оттенков, то при квантовании цвета не имеет смысла делать больше градаций.
Преимущества цифрового представления сигнала: высокая помехоустойчивость, универсальность, простота и надежность устройств, обрабатывающих информацию.
Характеристика процесса передачи данных. Каналы передачи данных. Способы передачи информации.
Американским ученым, одним из основателей теории информации, Клодом Шенноном была предложена схема процесса передачи информации по техническим каналам связи, представленная на рисунке 27:
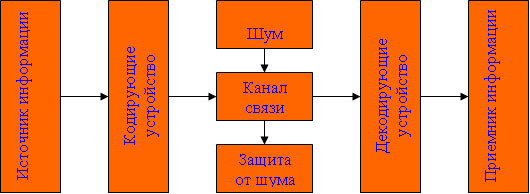
Рисунок 27. Схема технической системы передачи информации.
Работу такой схемы можно пояснить на знакомом всем процессе разговора по телефону. Источником информации является говорящий человек. Кодирующим устройством - микрофон телефонной трубки, с помощью которого звуковые волны (речь) преобразуются в электрические сигналы. Каналом связи является телефонная сеть (провода, коммутаторы телефонных узлов, через которые проходит сигнал). Декодирующим устройством является телефонная трубка (наушник) слушающего человека - приемника информации. Здесь пришедший электрический сигнал превращается в звук.
Связь, при которой передача производится в форме непрерывного электрического сигнала, называется аналоговой связью.
Под кодированием понимается любое преобразование информации, идущей от источника, в форму, пригодную для ее передачи по каналу связи. На заре эры радиосвязи применялся код азбуки Морзе. Текст преобразовывался в последовательность точек и тире, (коротких и длинных сигналов) и передавался в эфир. Принимавший на слух такую передачу человек должен был суметь декодировать код обратно в текст. Еще раньше азбука Морзе использовалась в телеграфной связи. Передача информации с помощью азбуки Морзе - это пример дискретной связи.
В настоящее время широко используется цифровая связь, когда передаваемая информация кодируется в двоичную форму (0 и 1 - двоичные цифры), а затем декодируется в текст, зображение, звук. Цифровая связь, очевидно, тоже является дискретной.
Термином «шум» называют разного рода помехи, искажающие передаваемый сигнал и приводящие к потере информации. Такие помехи прежде всего возникают по техническим причинам: плохое качество линий связи, незащищенность друг от друга различных потоков информации, передаваемых по одним и тем же каналам. Часто, беседуя по телефону, мы слышим шум, треск, мешающие понять собеседника, или на наш разговор накладывается разговор совсем других людей. В таких случаях необходима защита от шума
В первую очередь применяются технические способы защиты каналов связи от воздействия шумов. Такие способы бывают самые разные, иногда - простые, иногда - очень сложные. Например, использование экранированного кабеля вместо «голого» провода; применение разного рода фильтров, отделяющих полезный сигнал от шума.
Клодом Шенноном была разработана специальная теория кодирования, дающая методы борьбы с шумом. Одна из важных идей этой теории состоит в том, что передаваемый по линии связи код должен быть избыточным. За счет этого потеря какой-то части информации при передаче может быть компенсирована. Например, если при разговоре по телефону вас плохо слышно, то, повторяя каждое слово дважды, вы имеете больше шансов на то, что собеседник поймет вас правильно.
Однако нельзя делать избыточность слишком большой. Это приведет к задержкам и удорожанию связи. Теория кодирования К.Шеннона как раз и позволяет получить такой код, который будет оптимальным. При этом избыточность передаваемой информации будет минимально возможной, а достоверность принятой информации - максимальной.
В современных системах цифровой связи часто применяется следующий прием борьбы с потерей информации при передаче. Все сообщение разбивается на порции - блоки. Для каждого блока вычисляется контрольная сумма (сумма двоичных цифр), которая передается вместе с данным блоком. В месте приема заново вычисляется контрольная сумма принятого блока, и если она не совпадает с первоначальной, то передача данного блока повторяется. Так будет происходить до тех пор, пока исходная и конечная контрольные суммы не совпадут.
Каналы передачи информации
Каналы передачи информации предназначены для передачи сообщений от источника к потребителю. При заданных характеристиках линий связи основными задачами являются анализ и синтез операторов преобразования сигналов на передающей и приемной стороне, которые определяются видом канала передачи информации.
Виды каналов передачи информации.
По назначению каналы передачи информации подразделяются на телефонные, телеметрические, передачи цифровых данных и др. В зависимости от характера линий связи различают каналы радиосвязи и каналы проводной связи: кабельные, волноводные, волоконно-оптические и др. Наилучшими характеристиками обладают кабельные линии связи, работающие в диапазоне частот от сотен килогерц до десятков мегагерц.
Каналы радиосвязи различных частотных диапазонов во многих случаях позволяют организовать дальнюю связь без промежуточных станций и поэтому являются более экономичными по сравнению с кабельными.
Наибольшее распространение в многоканальной телефонной и телевизионной связи получили наземные радиорелейные линии связи, работающие в диапазоне частот от десятков мегагерц до десятков гигагерц
Спутниковые линии связи по принципу работы представляют собой разновидность радиорелейных линий с ретрансляторами, установленными на искусственных спутниках Земли, что обеспечивает дальность связи около 10000 км для каждого спутника. Диапазон частот спутниковой связи в настоящее время расширен до 250 ГГц, что обеспечивает повышение качественных показателей систем связи.
Переход на более высокочастотные диапазоны позволяет получить остронаправленное излучение при малых размерах антенн, уменьшить влияние атмосферных и промышленных помех, организовать большое число широкополосных каналов связи.
По характеру сигналов на входе и выходе каналов различают дискретные, непрерывные и дискретно-непрерывные каналы.
Волоконно-оптические каналы передачи информации.
Волоконно-оптические системы связи и передачи информации широко применяются в технике дальней связи, кабельном телевидении и компьютерных сетях. Волоконно-оптические каналы передачи информации содержат все элементы, характерные для систем связи, представленные схемой рис. 28, и являются примером реализации каналов связи и передачи информации на основе высоких технологий.
Достоинствами оптических кабелей по сравнению с электрическими являются возможность передачи большого потока информации, малое ослабление сигнала и независимость его от частоты в широком диапазоне частот, высокая защищенность от внешних электоромагнитных помех, малые габаритные размеры и масса (масса оптических кабелей в 10 раз меньше электрических). Оптические кабели не требуют дорогостоящих материалов и изготавливаются, как правило, из стекла или полимеров.
В оптических системах передачи информации применяются в основном те же принципы образования многоканальной связи, что и в обычных системах передачи по электрическим кабелям, а именно частотного и временного разделения каналов. В первом случае сигналы различаются по частоте и имеют аналоговую форму передаваемого сообщения. Во втором случае каналы мультиплексируются во времени, и импульсы имеют дискретный вид. Это соответствует цифровой передаче с импульсно-кодовой модуляцией (ИКМ).
Во всех случаях оптической передачи информации электрический сигнал, формируемый частотным или временным методом, модулирует оптическую несущую и затем передается по оптическому кабелю.
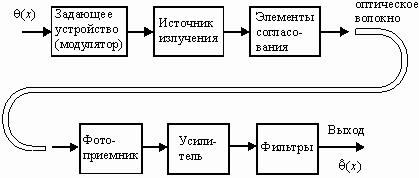
Рисунок 28. Структурная схема волоконно-оптического канала передачи информации.
Возможны два вида модуляции: внутренняя и внешняя. При внутренней модуляции электрический сигнал непосредственно воздействует на излучение источника (лазера), обеспечивая соответствующую интенсивность и форму сигнала. При внешней модуляции используется специальное модулирующее устройство, с помощью которого осуществляется воздействие передаваемого сигнала на уже сформированный световой луч. Для систем с полупроводниковыми лазерами применяется, как правило, внутренняя модуляция.
В основном используется метод модуляции интенсивности оптической несущей, при котором от амплитуды электрического сигнала зависит мощность излучения, подаваемого в кабель, и закон изменения мощности оптического излучения повторяет закон изменения модулирующего сигнала. Частотная и фазовая модуляция не могут быть применены непосредственно, поскольку из-за шумового характера излучения полупроводниковых источников, работающих в оптическом диапазоне, сигнал не является строго синусоидальным. Тем не менее, эти виды модуляции в принципе могут быть реализованы путем изменения соответствующих параметров сигнала, модулирующего интенсивность излучения.
Выбор метода модуляции интенсивности излучения для оптических систем обусловлен также простотой реализации передачи и приема сигнала. При передаче используется полупроводниковый лазер, который обеспечивает непосредственное преобразование электрического сигнала в оптический, сохраняя его форму. Для повышения эффективности ввода оптического сигнала в кабель (снижения потерь) в схеме рис. 28 используются элементы согласования. Поступающий из кабеля оптический сигнал преобразуется в оптическом приемнике в электрический сигнал, который поступает для дальнейших преобразований в электронную схему. Прием осуществляется фотодетектором, выходной ток которого пропорционален входной мощности. Следовательно, подавая оптический сигнал непосредственно на фоточувствительную поверхность фотодетектора, можно преобразовать его в электрический сигнал сохраняя его форму.
Оптические системы передачи являются, как правило, цифровыми. Это обусловлено тем, что передача аналоговых сигналов требует высокой степени линейности промежуточных усилителей, которую трудно обеспечить в оптических системах. Особенность оптических цифровых методов состоит в том, что передача ведется только однополярными импульсами электрического сигнала, модулирующего оптическую несущую. Последнее объясняется тем, что модулируется не амплитуда, а мощность оптического излучения.
Таким образом, наиболее распространенной волоконно-оптической системой связи является в настоящее время цифровая система с временным разделением каналов и ИКМ интенсивности излучения источника. Двухсторонняя связь осуществляется по двум волоконным световодам. По одному световоду передаются сигналы в направлении А-Б, по другому в направлении Б-А. В обоих направлениях сигналы передаются на одной и той же оптический несущей (например, имеющей частоту v=2,3 ×1014 Гц, соответствующую длине волны ?=1,3 мкм).
Источники и приемники излучения должны быть взаимно согласованными с кабелем. Для этого необходимо, чтобы:
-
длина волны излучения находилась в области малого затухания кабеля;
-
диаграмма направленности излучения источника соответствовала апертурному углу выбранного световода;
-
фотоприемник имел достаточную чувствительность;
-
соблюдалось соответствие между скоростью передачи информации и шириной спектра излучения источника.
Следует иметь в виду, что в связи с сильно выраженными дисперсионными свойствами оптического кабеля приходящие на фотодетектор импульсы могут перекрываться, поэтому требуется использовать специальные алгоритмы оптимального приёма. Для подавления межсимвольной интерференции применяют фильтры (выравниватели), которые располагают после фотодетектора и усилителя. Последующую часть электрической схемы оптимизируют для приема импульсов без межсимвольной интерференции.
Расширение импульсов при передачи их по оптическому кабелю эквивалентно их прохождению через четырехполюстник с частотной характеристикой, спадающей в области высоких частот. Для ее выравнивания применяют фильтры, значение коэффициента передачи которых с частотой возрастает, что приводит также к увеличению уровня шума. Поэтому характеристику выравнивателя подбирают как компромисс между снижением межсимвольной помехи и возрастанием уровня шумов (связанных с фотодетектированием и усилением) по минимальному уровню требуемой световой мощности на входе фотодетектора.
Весьма перспективно применение спектрального уплотнения, при котором в волоконный световод вводится одновременно излучение от нескольких источников, работающих на различных оптических частотах, а на приемной стороне с помощью оптических фильтров происходит разделение сигналов. За счет спектрального уплотнения возможна передача значительно большего объема информации по одному волоконному световоду и организация по нему двухсторонней связи.
Информация и вероятность. Пропускная способность канала связи.
Равновероятные события - это события, которые не имеют преимущества друг перед другом, т.е. вероятность их появления не зависит от условий проведе-ния эксперимента (выпадение орла или решки, выпадение любой из шести граней кубика).
Неравновероятные события - это события, вероятность появления которых зависит от условий проведения эксперимента (зависимость прогноза погода от времени года).
ВЕРОЯТНОСТЬ какого - либо случайного события P определяется как от-ношение числа случаев К, соответствующих наступлению ожидаемого события, к общему числу возможных случаев N, если случаи равновозможны (равновероятны):
P = K / N
Пропускная способность - метрическая характеристика, показывающая соотношение количества проходящих единиц (информации, предметов, объёма) в единицу времени через канал, систему, узел.
Пропускная способность канала
Скорость передачи информации зависит в значительной степени от скорости её создания, способов кодирования и декодирования. Наибольшая возможная в данном канале скорость передачи информации называется его пропускной способностью. Пропускная способность канала, по определению, есть скорость передачи информации при использовании «наилучших» для данного канала источника, кодера и декодера, поэтому она характеризует только канал.
Пропускная способность дискретного (цифрового) канала без помех
C = log(m) бит/символ
где m - основание кода сигнала, используемого в канале. Скорость передачи информации в дискретном канале без шумов равна его пропускной способности, когда символы в канале независимы, а все m букв алфавита равновероятны (используются одинаково часто).
Введение понятий энтропии, количества информации, скорости выдачи информации источником, избыточности позволяют характеризовать свойства информационных систем. Однако для сравнения информационных систем только такого описания недостаточно. Обычно нас интересует не только передача данного количества информации, но передача его в возможно более короткий срок; не только хранение определенного количества информации, но хранение с помощью минимальной по объему аппаратуры и т.п.
Пусть количество информации, которое передается по каналу связи за время Т равно
Если передача сообщения длится Т единиц времени, то скорость передачи информации составит .
Это количество информации, приходящееся в среднем на одно сообщение. Если в секунду передается n сообщений, то скорость передачи будет составлять
Пропускная способность канала есть максимально достижимая для данного канала скорость передачи информации:
Или максимальное количество информации, передаваемое за единицу времени:
Скорость передачи может быть технической или информационной.
Под технической скоростью VT, называемой также скоростью манипуляции, подразумевается число элементарных сигналов (символов), передаваемых в единицу времени бод.
Информационная скорость или скорость передачи информации, определяется средним количеством информации, которое передается в единицу времени и измеряется (бит/сек). R=nH.
Для равновероятных сообщений составленных из равновероятных взаимно независимых символов
В случае если символы не равновероятны
В случае если символы имеют разную длительность
Выражение для пропускной способности отличается тем, что характеризуется максимальной энтропией бит/сек
Для двоичного кода бит/сек
Пропускная способность является важнейшей характеристикой каналов связи. Возникает вопрос: какова должна быть пропускная способность канала, чтобы информация от источника X к приемнику Y поступала без задержек? Ответ на этот вопрос дает 1ая теорема Шеннона.
Теорема Шеннона.
Теорема Шеннона, одна из основных теорем теории информации о передаче сигналов по каналам связи при наличии помех, приводящих к искажениям.
Пусть надлежит передать последовательность символов, появляющихся с определёнными вероятностями, причём имеется некоторая вероятность того, что передаваемый символ в процессе передачи будет искажён.
Простейший способ, позволяющий надёжно восстановить исходную последовательность по получаемой, состоит в том, чтобы каждый передаваемый символ повторять большое число (N) раз. Однако это приведёт к уменьшению скорости передачи в N раз, т. е. сделает её близкой к нулю.
Ш. т. утверждает, что можно указать такое, зависящее только от рассматриваемых вероятностей положительное число v, что при сколько угодно малом существуют способы передачи со скоростью v'(v' < v), сколь угодно близкой к v, дающие возможность восстанавливать исходную последовательность с вероятностью ошибки, меньшей e. В то же время при скорости передачи v', большей v, это уже невозможно. Упомянутые способы передачи используют надлежащие «помехоустойчивые» коды. Критическая скорость v определяется из соотношения Hv = C, где Н - энтропия источника на символ, С - ёмкость канала в двоичных единицах в секунду.
Понятие об оптимальном кодировании информации.
В компьютере информация представляется в двоичном виде, и, вообще говоря, кодирование информации в ЭВМ - одна из задач теории кодирования.
Теория кодирования - один из разделов теоретической информатики. Одна из задач - разработка принципов наиболее экономичного кодирования. Эта задача касается передачи, обработки, хранения информации. Частное ее решение - представление информации в компьютере.
Источник представляет сообщение в алфавите, который называется первичным, далее это сообщение попадает в устройство, преобразующее и представляющее его во вторичном алфавите.
Код - правило, описывающее соответствие знаков (или их сочетаний) первичного алфавита знаком (их сочетаниями) вторичного алфавита.
Кодирование - перевод информации, представленной сообщением в первичном алфавите, в последовательность кодов.
Декодирование - операция обратная кодированию.
Кодер - устройство, обеспечивающее выполнение операции кодирования.
Декодер - устройство, производящее декодирование.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечит возврат к исходной информации без каких-либо ее потерь.
Пример обратимого: слова - телеграфный код.
необратимого: английский - русский - здесь неоднозначно.
Далее будем иметь в виду только обратимое кодирование.
Математическая постановка условия обратимого кодирования.
Пусть первичный алфавит А состоит из N знаков со средней информацией на знак IA , вторичный В - из М знаков со средней информацией на знак IB .
Пусть сообщение в первичном алфавите содержит n знаков, а закодированное - m знаков. Если исходное сообщение содержит IS (A) информации, а закодированное If (B), то условие обратимости кодирования (то есть неисчезновения информации при кодировании) очевидно может быть записано так:
IS(A) < If (B) - то есть операция обратимого кодирования может увеличить количество информации в сообщении, но не может уменьшить ее.
n* I(A) < m* I(B) (заменили произведением числа знаков на среднее информационное содержание знака).
Отношение m/n -характеризует среднее число знаков вторичного алфавита, который используется для кодирования одного знака первичного. Обозначим его К(А,В)
К(А,В) > I(A) / I(B) . Обычно К(А,В) >1 => знак первичного алфавита кодируется несколькими вторичными =>? - проблема выбора наилучшего варианта - оптимального кода.
Оптимальность- это экономический фактор (меньше энергии, времени, объема носителя - уже в зависимости от задачи и поставленных ограничений).
Минимально возможная длина кода: Кmin (А,В)= I(A) / I(B)-это нижний предел длины кода. Но реально в схемах кодирования как близко возможное приближение К(А,В) к Кmin (А,В).
Кодирование символьной и числовой информации.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, то есть I= 1 байт = 8 битов.
Для кодирования одного символа требуется 1 байт информации.
Если рассматривать символы как возможные события, то по формуле N=2I можно вычислить, какое количество различных символов можно закодировать:
N=2I=28=256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или в соответсвующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертаниям, а компьютер - по их кодам.
При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа преобразуется в его двоичный код. Пользователь нажимает на клавиатуре клавишу с символом, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает один байт.
В процессе вывода символа на экран компьютера производится обратный процесс - декодирование, то есть преобразование кода символа в его изображение.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, то есть в национальных кодировках одному и тому же коду соответствуют различные символы. К сожалению, в настоящее время существует пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Мас, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а N=216=65536 различных символов. Эту кодировку поддерживают последние версии платформы Microsoft Windows&Office (начиная с 1997 года).
Каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Таблица 9. Кодировки символов
|
Двоичный код |
Десятичный код |
КОИ8 |
СР1251 |
СР866 |
Мас |
ISO |
|
00000000 |
0 |
. | ||||
|
......... |
. |
. | ||||
|
00001000 |
8 |
Удаление последнего символа (клавиша Backspace) | ||||
|
...... |
. |
. | ||||
|
00001101 |
13 |
Перевод строки (клавиша Enter) | ||||
|
....... |
. |
. | ||||
|
00100000 |
32 |
Пробел | ||||
|
00100001 |
33 |
! | ||||
|
...... |
. |
. | ||||
|
01011010 |
90 |
Z | ||||
|
...... |
. |
. | ||||
|
01111111 |
127 |
D | ||||
|
10000000 |
128 |
- |
Ъ |
А |
А |
к |
|
...... |
..... |
..... |
...... |
..... |
..... |
...... |
|
11000010 |
194 |
б |
В |
- |
- |
Т |
|
...... |
..... |
..... |
...... |
..... |
..... |
...... |
|
11001100 |
204 |
л |
М |
) |
) |
Ь |
|
...... |
..... |
..... |
...... |
..... |
..... |
...... |
|
11011101 |
221 |
щ |
Э |
_ |
Е |
н |
|
...... |
..... |
..... |
...... |
..... |
..... |
...... |
|
11111111 |
225 |
ь |
я |
неразделенный пробел |
неразделенный пробел |
п |
Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ», тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов. Так как это делают специальные программы-конверторы, встроенные в приложения.
Кодирование графической информации.
Пространственная дискретизация. В процессе кодирования изображения производится его пространственная дискретизация. Пространственную дискретизацию изображения можно сравнить с построением изображения из мозаики (большого количества маленьких разноцветных стекол). Изображение разбивается на отдельные маленькие фрагменты (точки), причем каждому фрагменту присваивается значение его цвета, то есть код цвета (красный, зеленый, синий и так далее).
Качество кодирования изображения зависит от двух параметров. Во-первых, качество кодирования изображения тем выше, чем меньше размер точки и соответственно большее количество точек составляет изображение.
Во-вторых, чем большее количество цветов, то есть большее количество возможных состояний точки изображения, используется, тем более качественно кодируется изображение (каждая точка несет большее количество информации). Совокупность используемых в наборе цветов образует палитру цветов.
Формирование растрового изображения.
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые в свою очередь содержат определенное количество точек (пикселей).
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Качество изображения определяется разрешающей способностью монитора, т.е. количеством точек, из которых оно складывается. Чем больше разрешающая способность, то есть чем больше количество строк растра и точек в строке, тем выше качество изображения. В современных персональных компьютерах обычно используются три основные разрешающие способности экрана: 800 на 600, 1024 на 768, 1280 на 1024 точки
Рассмотрим формирование на экране монитора растрового изображения, состоящего из 600 строк по 800 точек в каждой строке (всего 480000 точек). В простейшем случае (черно-белое изображение без градаций серого цвета) каждая точка экрана может иметь одно из двух состояний - «черная» или «белая», то есть для хранения ее состояния необходим 1 бит.
Цветные изображения формируются в соответствии с двоичным кодом цвета каждой точки, хранящимся в видеопамяти. Цветные изображения могут иметь различную глубину цвета, которая задается количеством битов, используемым для кодирования цвета точки. Наиболее распространенными значениями глубины цвета являются 8, 16, 24 или 32 бита.
Таблица 10. Формирование растрового изображения.
№ точки
Двоичный код цвета точки
1
0101101
2
00100101
...
...
800
11110000
...
...
480000
11001100
Качество двоичного кодирования изображения определяется разрешающей способностью экрана и глубиной цвета.
Каждый цвет можно рассматривать как возможное состояние точки, тогда количество цветов, отображаемых на экране монитора, может быть вычислено по формуле:
N=2I, где I - глубина цвета.
Таблица 11. Глубина цвета и количество отображаемых цветов.
Количество отображаемых цветов (N)
8
28=256
16(High Color)
216=65536
24(True Color)
224=16777216
32(True Color)
232=4294967296
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого и синего. Такая цветовая модель называется RGB-моделью по первым буквам английских названий цветов.
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности. Например, при глубине цвета в 24 бита на каждый из цветов выделяется по 8 бит, то есть для каждого из цветов возможны N=28=256 уровней интенсивности, заданные двоичными кодами (от минимальной - 00000000 до максимальной - 11111111).
Таблица 12. Формирование цветов при глубине цвета 24 бита
Интенсивность
Красный
Зеленый
Синий
Черный
00000000
00000000
00000000
Красный
11111111
00000000
00000000
Зеленый
00000000
11111111
00000000
Синий
00000000
00000000
11111111
Голубой
00000000
11111111
11111111
Желтый
11111111
11111111
00000000
Белый
11111111
11111111
11111111
Графический режим.
Графический режим вывода изображения на экран монитора определяется величиной разрешающей способности и глубиной цвета. Для того чтобы на экране монитора формировалось изображение, информация о каждой его точке (код цвета точки) должна храниться в видеопамяти компьютера. Рассчитаем необходимый объем видеопамяти для одного из графических режимов, например, с разрешением 800 на 600 точек и глубиной цвета 24 бита на точку.
Всего точек на экране: 800×600=480000.
Необходимый объем видеопамяти:
24 бит × 480000=11520000 бит=1440000 байт=1406,25 Кбайт=1,37 Мбайт.
Аналогично рассчитывается необходимый объем видеопамяти для других графических режимов.
В Windows предусмотрена возможность выбора графического режима и настройки параметров видеосистемы компьютера, включающей монитор и видео-адаптер.
Кодирование звуковой и видеоинформации.
Временная дискретизация звука. Звук представляет собой звуковую волну с непрерывно меняющейся амплитудой и частотой. Чем больше амплитуда сигнала, тем он громче для человека, чем больше частота сигнала, тем выше тон. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть превращен в последовательность электрических импульсов (двоичных нулей и единиц).
В процессе кодирования непрерывного звукового сигнала производится его временная дискретизация. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, причем для каждого такого участка устанавливается определенная величина амплитуды.
Таким образом, непрерывная зависимость амплитуды сигнала от времени А(t) заменяется на дискретную последовательность уровней громкости. На графике это выглядит как замена гладкой кривой на последовательность «ступенек».
Рисунок 7. Временная дискретизация звука.
Каждой «ступеньке» присваивается значение уровня громкости звука, его код (1, 2, 3 и т.д.) уровни громкости звука можно рассматривать как набор возможных состояний, соответственно, чем большее количество уровней будет выделено в процессе кодирования, тем большее количество информации будет нести значение каждого уровня и тем более качественным будет звучание.
Современные звуковые карты обеспечивают 16-битную глубину кодирования звука.
Количество различных уровней сигнала
Количество различных уровней сигнала (состояний при данном кодировании) можно рассчитать по формуле:
N=2I=216=65536, где I-глубина звука.
Таким образом, современные звуковые карты могут обеспечить кодирование 65536 уровней сигнала. Каждому значению амплитуды звукового сигнала присваивается 16-битный код.
При двоичном кодировании непрерывного звукового сигнала он заменяется последовательностью дискретных уровней сигнала. Качество кодирования зависит от количества измерений уровня сигнала в единицу времени, то есть частоты дискретизации. Чем большее количество измерений производится за 1 секунду (чем больше частота дискретизации), тем точнее процедура двоичного кодирования.
Качество двоичного кодирования звука определяется глубиной кодирования и частотой дискретизации.
Количество измерений в секунду может лежать в диапазоне от 8000 до 48000, то есть частота дискретизации аналогового звукового сигнала может принимать значения от 8 до 48 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц - качество звучания аудио-CD. Следует также учитывать, что возможны как можно-, так и стерео-режимы.
Можно оценить информационный объем стереоаудиофайла длительностью звучания 1 секунда при высоком качестве звука (16 битов, 48 кГц). Для этого количество битов, приходящихся на одну выборку, необходимо умножить на коли-чество выборок в 1 секунду и умножить на 2 (стерео):
16 бит × 48000×2=1536000 бит=192000 байт=187,5 Кбайт.
Стандартное приложение Звукозапись играет роль цифрового магнитофона и позволяет записывать звук, то есть дискретизировать звуковые файлы, и сохранять их в звуковых файлах в формате WAV. Эта программа позволяет редактировать звуковые файлы, микшировать их (накладывать друг на друга), а также воспроизводить.
Кодирование видеоинформации
Видеоинформация включает в себя последовательность кадров и звуковое сопровождение.
Так как объемом звуковой составляющей видеоклипа можно пренебречь, то объем видеофайла примерно равен произведению количества информации в каждом кадре на число кадров.
Число кадров вычисляется как произведение длительности видеоклипа t на скорость кадров v, то есть их количество в 1 с: V=N×M×C×v×t.
При разрешении 800×600 точек, разрядности цвета C=16, скорости кадров v=25 кадров/c, видеоклип длительностью 30 с будет иметь объем: V=800×600×16×25×30=576×107(бит) =72×107 (байт)=687 (Мбайт).
Методы сжатия информации.
Существует много разных практических методов сжатия без потери информации, которые, как правило, имеют разную эффективность для разных типов данных и разных объемов. Однако, в основе этих методов лежат три теоретических алгоритма:
-
алгоритм RLE(Run Length Encoding);
-
алгоритмы группы KWE(KeyWord Encoding);
-
алгоритм Хаффмана.
Алгоритм RLE
В основе алгоритма RLE лежит идея выявления повторяющихся последовательностей данных и замены их более простой структурой, в которой указывается код данных и коэффициент повторения. Например, пусть задана такая последовательность данных, что подлежит сжатию:
1 1 1 1 2 2 3 4 4 4
В алгоритме RLE предлагается заменить ее следующей структурой: 1 4 2 2 3 1 4 3, где первое число каждой пары чисел - это код данных, а второе - коэффициент повторения. Если для хранения каждого элемента данных входной последовательности отводится 1 байт, то вся последовательность будет занимать 10 байт памяти, тогда как выходная последовательность (сжатый вариант) будет занимать 8 байт памяти. Коэффициент сжатия, характеризующий степень сжатия, можно вычислить по формуле:
где Vx - объем памяти, необходимый для хранения выходной (результирующей) последовательности данных, Vn - входной последовательности данных.
Чем меньше значение коэффициента сжатия, тем эффективней метод сжатия. Понятно, что алгоритм RLE будет давать лучший эффект сжатия при большей длине повторяющейся последовательности данных. В случае рассмотренного выше примера, если входная последовательность будет иметь такой вид: 1 1 1 1 1 1 3 4 4 4, то коэффициент сжатия будет равен 60%. В связи с этим большая эффективность алгоритма RLE достигается при сжатии графических данных (в особенности для однотонных изображений).
Алгоритм группы KWE
В основе алгоритма сжатия по ключевым словам положен принцип кодирования лексических единиц группами байт фиксированной длины. Примером лексической единицы может быть обычное слово. На практике, на роль лексических единиц выбираются повторяющиеся последовательности символов, которые кодируются цепочкой символов (кодом) меньшей длины. Результат кодирования помещается в таблице, образовывая так называемый словарь.
Существует довольно много реализаций этого алгоритма, среди которых наиболее распространенными являются алгоритм Лемпеля-Зіва (алгоритм LZ) и его модификация алгоритм Лемпеля-Зіва-Велча (алгоритм LZW). Словарем в данном алгоритме является потенциально бесконечный список фраз. Алгоритм начинает работу с почти пустым словарем, который содержит только одну закодированную строку, так называемая NULL-строка. При считывании очередного символа входной последовательности данных, он прибавляется к текущей строке. Процесс продолжается до тех пор, пока текущая строка соответствует какой-нибудь фразе из словаря. Но рано или поздно текущая строка перестает соответствовать какой-нибудь фразе словаря. В момент, когда текущая строка представляет собой последнее совпадение со словарем плюс только что прочитанный символ сообщения, кодер выдает код, который состоит из индекса совпадения и следующего за ним символа, который нарушил совпадение строк. Новая фраза, состоящая из индекса совпадения и следующего за ним символа, прибавляется в словарь. В следующий раз, если эта фраза появится в сообщении, она может быть использована для построения более длинной фразы, что повышает меру сжатия информации.
Алгоритм Хаффмана
В основе алгоритма Хаффмана лежит идея кодирования битовыми группами. Сначала проводится частотный анализ входной последовательности данных, то есть устанавливается частота вхождения каждого символа, встречающегося в ней. После этого, символы сортируются по уменьшению частоты вхождения.
Основная идея состоит в следующем: чем чаще встречается символ, тем меньшим количеством бит он кодируется. Результат кодирования заносится в словарь, необходимый для декодирования. Рассмотрим простой пример, иллюстрирующий работу алгоритма Хаффмана.
Пусть задан текст, в котором бурва 'А' входит 10 раз, буква 'В' - 8 раз, 'С'- 6 раз , 'D' - 5 раз, 'Е' и 'F' - по 4 раза. Тогда один из возможных вариантов кодирования по алгоритму Хаффмана приведен в таблицы 13.
Таблица 13. Кодирование по алгоритму Хаффмана
Частота вхождения
Битовый код
А
10
00
В
8
01
С
6
100
D
5
101
E
4
110
F
4
111
Как видно из таблицы 13, размер входного текста до сжатия равен 37 байт, тогда как после сжатия - 93 бит, то есть около 12 байт (без учета длины словаря). Коэффициент сжатия равен 32%. Алгоритм Хаффмана универсальный, его можно применять для сжатия данных любых типов, но он малоэффективен для файлов маленьких размеров (за счет необходимости сохранение словаря).
На практике программные средства сжатия данных синтезируют эти три "чистых" алгоритмы, поскольку их эффективность зависит от типа и объема данных. В таблице 14 приведены распространенные форматы сжатия и соответствующие им программы - архиваторы, использующиеся на практике.
Таблица 14. Распространённые форматы сжатия
Операционная система MS DOS
Операционная система Windows
Программа архивации
Программа разархивации
Программа архивации
Программа разархивации
ARJ
Arj.exe
Arj.exe
WinArj.exe
WinArj.exe
RAR
Rar.exe
Unrar.exe
WinRar.exe
WinRar.exe
ZIP
Pkzip.exe
Pkunzip.exe
WinZip.exe
WinZip.exe
Кроме того, современные архиваторы предоставляют пользователю полный спектр услуг для работы с архивами, основными из которых являются :
-
создание нового архива;
-
добавление файлов в существующий архив;
-
распаковывание файлов из архива;
-
создание самораспаковающихся архивов (self-extractor archive);
-
создание распределенных архивов фиксированного размера для носителей маленькой емкости;
-
защита архивов паролями от несанкционированного доступа;
-
просмотр содержимого файлов разных форматов без предварительного распаковывания;
-
поиск файлов и данных внутри архива;
-
проверка на вирусы в архиве к распаковыванию;
выбор и настройка коэффициента сжатия.
Сжатие с потерей и без потери информации.
В зависимости от того, в каком объекте размещены данные, подлежащие сжатию различают:
-
Сжатие (архивация) файлов: используется для уменьшения размеров файлов при подготовке их к передаче каналами связи или к транспортированию на внешних носителях маленькой емкости;
-
Сжатие (архивация) папок: используется как средство уменьшения объема папок перед долгим хранением, например, при резервном копировании;
-
Сжатие (уплотнение) дисков: используется для повышения эффективности использования дискового просторную путем сжатия данных при записи их на носителе информации (как правило, средствами операционной системы).
Существует много практических алгоритмов сжатия данных, но все они базируются на трех теоретических способах уменьшения избыточности данных. Первый способ состоит в изменении содержимого данных, второй - в изменении структуры данных, а третий - в одновременном изменении как структуры, так и содержимого данных.
Если при сжатии данных происходит изменение их содержимого, то метод сжатия называется необратимым. Такие методы часто называются методами сжатия с регулированными потерями информации. Понятно, что эти методы можно применять только для таких типов данных, для которых потеря части содержимого не приводит к существенному искажению информации. К таким типам данных относятся видео- и аудиоданные, а также графические данные. Методы сжатия с регулированными потерями информации обеспечивают значительно большую степень сжатия, но их нельзя применять к текстовым данным. Примерами форматов сжатия с потерями информации могут быть:
JPEG - для графических данных;
MPG - для для видеоданных;
MP3 - для аудиоданных.
Если при сжатии данных происходит только изменение структуры данных, то метод сжатия называется обратимым. В этом случае, из архива можно восстановить информацию полностью. Обратимые методы сжатия можно применять к любым типам данных, но они дают меньшую степень сжатия по сравнению с необратимыми методами сжатия. Примеры форматов сжатия без потери информации:
GIF, TIFF - для графических данных;
AVI - для видеоданных;
ZIP, ARJ, RAR, CAB, LH - для произвольных типов данных.
Методы сжатия растровой информации делятся на две большие группы: сжатие с потерями и сжатие без потерь. Методы сжатия без потерь дают более низкий коэффициент сжатия, но зато сохраняют точное значение пикселов исходного изображения. Методы с потерями дают более высокие коэффициенты сжатия, но не позволяют воспроизвести первоначальное изображение с точностью до пиксела. Для файлов, создаваемых программами автоматизированного проектирования или электронных таблиц, очень важно сохранить всю информацию, потому что потеря хотя бы одного бита может изменить смысл всего файла. Совсем другое дело с растровыми данными. Человеческий глаз не воспринимает все тонкие оттенки цвета в обычном растровом изображении. Таким образом, некоторые детали могут быть опущены без видимого нарушения информационного содержания картинки.
Сначала познакомимся с одним из вариантов группового кодирования (run-lenght encoding - RLE). Идея метода заключается в том, что последовательность повторяющихся значений заменяется парой чисел: одно из них указывает длину группы (число повторений данного значения), а другое - собственно это значение. Это очень общий и очень простой метод без потерь. В том или ином виде он используется во многих популярных сегодня форматах графических файлов и, в частности, в PCX и BMP. В его основе лежит тот факт, что многие изображения избыточны, поскольку содержат большое количество смежных пикселов одного цвета. Посмотрим, например, как с помощью группового кодирования сжимается изображение, в котором встречается подряд 100 пикселов с нулевым значением. Эта последовательность из 100 нулей кодируется парой чисел (100,0). Следовательно такой фрагмент картинки сократится в пятьдесят раз.
Другим методом, которому мы также уделим внимание, будет JPEG - метод, сжимающий с потерями. Метод получил свое название от аббревиатуры объединенной группы экспертов в области фотографии (Joint Photographic Expert Group - JPEG), которая его и разработала. JPEG широко используется при сжатии статических изображений для их хранения на компакт-дисках. Этот метод существенно более сложен, чем RLE. Основная идея метода разделить информацию в изображении по уровню важности, и затем отбросить менее важную ее часть, уменьшая тем самым общий объем хранимых данных. Это достигается преобразованием матрицы цветовых значений в матрицу амплитуд, которые соответствуют определенным частотам разложения изображения. (Звуковые колебания, например, можно разложить математическими методами на простые синусоидальные гармоники различных амплитуд и частот, которые при сложении воспроизводят исходный сигнал. Строку или столбец пикселов изображения тоже можно представить амплитудами и частотами. Речь здесь идет не о спектральном составе света, а о форме воображаемых кривых, которые образуют графики, если значения пикселов служат ординатами. Отметим, что формула преобразования матрицы пикселов в матрицу амплитуд совсем не проста.)
JPEG-сжатие отбрасывает часть высокочастотных компонент изображения, оставляя компоненты с низкими частотами. Человеческий глаз менее чувствителен к высокочастотным вариациям цвета, поскольку общий вид изображения определяется низкими частотами. Значение пиксела, полученное при восстановлении изображения, несколько отличается от исходного значения, так как часть информации была потеряна, хотя обычно они очень близки.
У метода JPEG есть очень интересная особенность: пользователь может задавать коэффициент качества. Высокий коэффициент качества позволяет сохранить больше деталей, но при этом уменьшается степень сжатия. При низком коэффициенте качества степень сжатия увеличивается, но изображение становится менее четким. И это естественно, чем ниже коэффициент качества, тем большее количество информации отбрасывается. Вопрос в том, как найти разумный баланс между степенью сжатия и качеством изображения. Возможно придется прибегнуть к методу проб и ошибок, поскольку эффект JPEG-сжатия неодинаков для разных изображений. Одни картинки можно сжать в десять раз без особого ухудшения качества, в других же, даже при вдвое меньшем коэффициенте сжатия, возникают недопустимые искажения.
Когда любой из методов (RLE или JPEG) применяется к полноцветному изображению, то красная, зеленая и синяя компоненты сжимаются независимо. Если в растровой картинке используется палитра или просто оттенки серого, то значения пикселов можно закодировать в один проход.
Приступим к детальному рассмотрению методов RLE и JPEG.
Как работает алгоритм группового кодирования
Если вы внимательно посмотрите на растровое изображение, то обнаружите, что пикселы одного цвета часто оказываются рядом друг с другом. Если начать с левого верхнего угла изображения и исследовать пикселы каждой строки, выписывая последовательно их значения слева направо, то можно заметить, что картинка состоит из множества отрезков, в которых повторяется одно и то число. Количество пикселов в отрезке будем называть длиной отрезка.
Начиная с первой строки, программа группового кодирования просматривает значения пикселов слева направо и ищет отрезки повторяющихся пикселов. Всякий раз, когда встречаются три или более идущих подряд пикселов с одинаковым значением, программа заменяет их парой чисел: первое число указывает длину отрезка, второе - значение пикселов. Число, определяющее длину отрезка, будем называть меткой отрезка. На рисунке такие метки обозначены треугольниками.
Чтобы идентифицировать серии неповторяющихся значений пикселов, программа также вставляет метки (на рисунке представлены квадратиками), указывающие количество таких значений в серии. Зарезервированный бит необходим для того, чтобы можно было отличить метку отрезка, от метки серии неповторяющихся значений. Например, в 8-ми битах можно специфицировать последовательности длиной до 127 пикселов (максимальное число, представимое 7-ю битами); восьмой бит в каждой метке может отличать отрезок от серии неповторяющихся пикселов. В нашем примере благодаря RLE-сжатию размер строки уменьшился с 32 до 19 байт, т.е. на 40 процентов. Точно так же обрабатывается каждая строка пикселов, и отрезки одинаковых значений пикселов сжимаются во всем изображении.
Графическая программа декодирует изображение, считывая сжатый файл и восстанавливая отрезки повторяющихся значений пикселов. Заметим, что восстановленное изображение полностью совпадает с оригиналом.
Как работает алгоритм JPEG
Прежде всего программа делит изображение на блоки - матрицы размером 8х8 пикселов. Поскольку при использовании метода JPEG время, затрачиваемое на сжатие изображения, пропорционально квадрату числа пикселов в блоке, обработка нескольких блоков меньшего размера делается значительно быстрее, чем обработка всего изображения целиком.
К значениям пикселов применяется формула, названная дискретным косинусоидальным преобразованием (Discrete Cosine Transform - DCT). DCT переводит матрицу значений пикселов 8х8 в матрицу значений амплитуд такой же размерности, соответствующую определенным частотам синусоидальных колебаний. Левый верхний угол матрицы соответствует низким частотам, а правый нижний - высоким.
Коэффициент качества, введенный пользователем, используется в простой формуле, которая генерирует значения элементов другой матрицы 8х8, названной матрицей квантования. Чем ниже коэффициент качества, тем большие значения будут иметь элементы матрицы.
Каждое значение в матрице, получившееся после DCT-преобразования, делится на соответствующее значение из матрицы квантования, затем округляется до ближайшего целого числа. Так как большие числа находятся в правой нижней половине матрицы квантования, то основная часть высокочастотной информации изображения будет отброшена. Поэтому нижняя правая часть матрицы пикселов будет состоять в основном из нулей.
Далее программа, двигаясь по матрице зигзагообразно, считывает элементы матрицы и кодирует их последовательно методами без потерь. Заметим, что сжатие существенно зависит от нулей в правой нижней половине матрицы. Чем ниже коэффициент качества, тем больше нулей в матрице и, следовательно, тем выше степень сжатия.
Декодирование JPEG-изображения начинается с шага обратного кодированию без потерь, в результате чего восстанавливается матрица квантования пикселов.
Значения из матрицы пикселов умножаются на значения из матрицы квантования, чтобы восстановить, насколько это возможно, матрицу, которая была вычислена на шаге применения DCT. На этапе квантования была потеряна некоторая часть информации, поэтому числа в матрице будут близки к первоначальным, но не будет абсолютного совпадения.
Обратная к DCT формула (IDCT) применяется к матрице для восстановления значений пикселов исходного изображения. Еще раз отметим, что полученные цвета не будут полностью соответствовать первоначальным из-за потери информации на шаге квантования. Восстановленное изображение, при сравнении с оригиналом, будет выглядеть несколько размытым и обесцвеченным.
</ СПИСОК ЛИТЕРАТУРЫ
-
Хэмминг Р.В. Теория кодирования и теория информации: Пер. с англ. - М.: Радио и связь, 2010 . - 176 с., ил.
-
Фомин С. В. Системы счисления. - М.: Наука, 2011
-
Андреева Е., Фалина И. Информатика: Системы счисления и компьютерная арифметика. - М.: ЛБЗ, 2009
-
Душин В.К. Теоретические основы информационных процессов и систем: Учебник.- Издательско-торговая корпорация «Дашков и К», 2008 . - 348 с.
-
Маскаева А.М. Основы теории информации. М. : Форум ИНФРА- М, 2014
-
Панин В.В. Основы теории информации. М.: БИНОМ Лаборатория знаний, 2012
-
Хохлов Г.И. Основы теории информации: учеб. / М.: Академия, 2008